library(sjPlot)
options(OutDec=",") #pour que le marqueur décimal soit une virgule
tab_xtab(var.row = erfi$AGE_DEP, #variable en ligne
var.col = erfi$FREQ_MERE, #variable en colonne
weight.by = erfi$poids12, #pondération
show.summary = FALSE, #ne pas afficher de test statistique
show.obs = FALSE, #ne pas afficher les effectifs
show.row.prc = TRUE, #afficher les % en ligne (pour afficher les % en colonne, utiliser show.col.prc = TRUE)
title = "Proportion d'enfants voyant au moins une fois par semaine leur mère selon l'âge au départ du foyer parental", #titre du tableau
var.labels = c("Age au départ du foyer parental", "Voit sa mère au moins une fois par semaine"), #labels pour les noms des variables
value.labels = list(c("Moins de 20 ans", "20-21", "22-23", "24-25", "26-29", "30 ans ou plus"), #labels pour les modalités
c("Non", "Oui")),
encoding = "UTF-8") #pour que les caractères accentués apparaissent correctementRépliquer les premiers résultats de l’article “À quelle fréquence voit-on ses parents?” (Arnaud Régnier-Loilier, 2006)
Objectif
L’objectif de cette partie de la formation est de reproduire le graphique suivant :
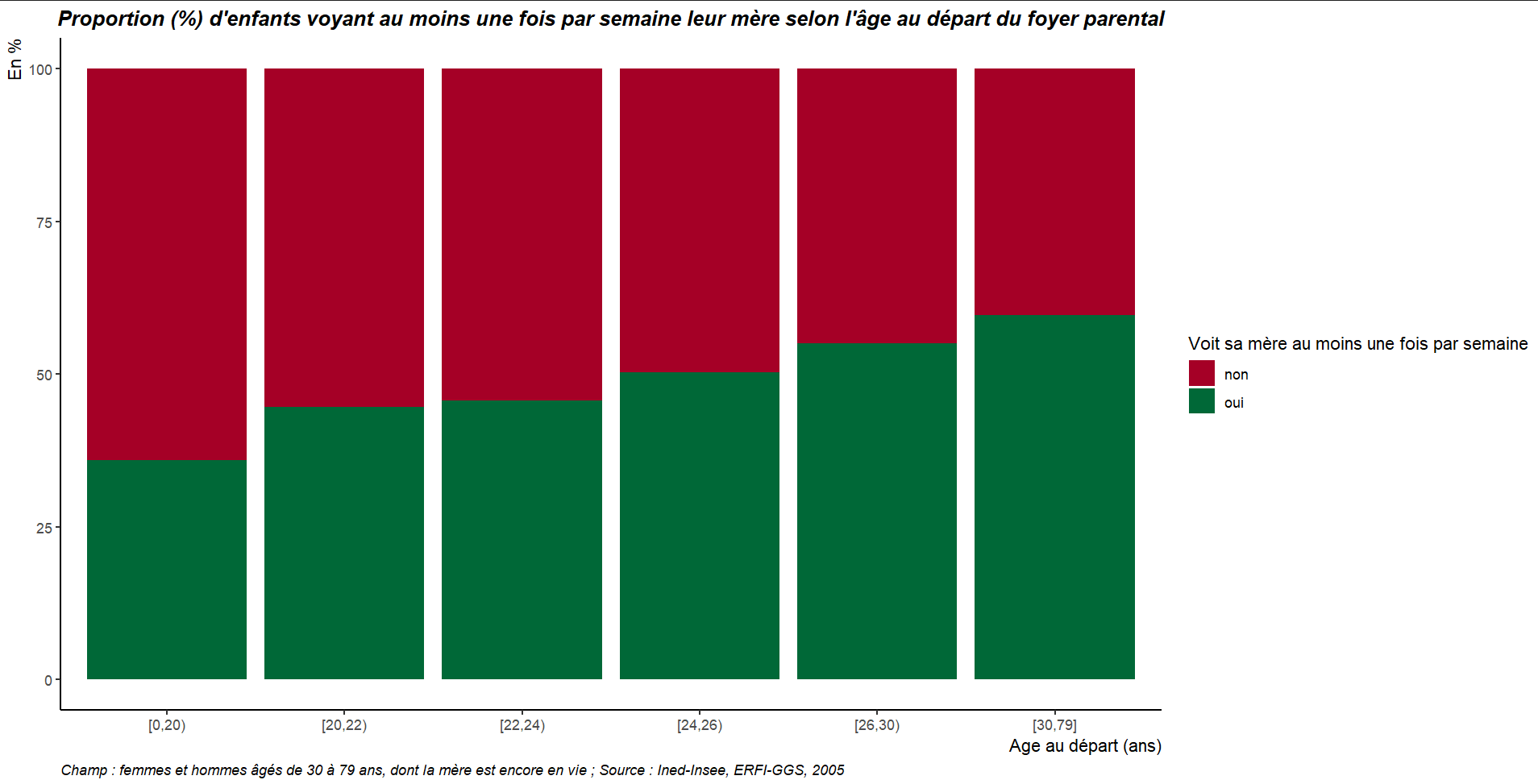
Il représente la proportion de personnes qui voient leur mère au moins une fois par semaine, selon l’âge au moment du départ du foyer parental. Il s’agit d’un extrait de la figure 1 de l’article de Population & Sociétés “A quelle fréquence voit-on ses parents ?”, présenté sous forme de diagramme en barre plutôt qu’une courbe afin de simplifier sa réalisation.
Outre la production du graphique, nous y associerons un tableau croisé, sans mise en forme, afin d’aider à l’interprétation, ou pour pouvoir citer certaines valeurs en appui d’un argumentaire.
Pour réaliser les traitements nécessaires à la reproduction du graphique, nous aurons besoin de consulter régulièrement le dictionnaire des codes du fichier de données anonymisées, disponible ici, ainsi que le questionnaire de l’enquête ERFI-1, disponible ici.
Il existe des packages R qui offrent des fonctions permettant de produire des tableaux mis en forme et prêts à être intégrés à des publications, rapports, ou supports de présentation. On peut citer par exemple gtsummary ou sjPlot. Leur usage nécessite d’être un minimum familier avec la programmation dans R, néanmoins de nombreuses ressources dédiées à ces packages sont disponibles sur Internet (en français ou en anglais).
Par exemple, voici le même tableau, produit avec la fonction tab_xtab du package sjPlot :
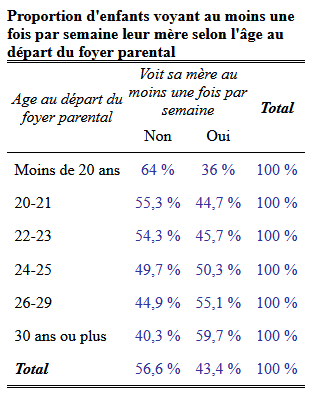
Ce tableau a été obtenu en exécutant ce code R :
On peut trouver une documentation relative au package sjPlot ici.
Sélection et exploration des variables
Le fichier de données contient 86 variables. Or, toutes ne sont pas nécessaires pour la réalisation de la figure souhaitée. De quelles variables avons-nous besoin ?
- Celles représentées dans le graphique : âge au départ du foyer parental (PF_AGEDEPFOY_rec), et fréquence de visite à la mère (PA_FQAVM_rec)
- Mais aussi, celles qui permettent de délimiter le champ, c’est-à-dire la population représentée dans le graphique : ici, il s’agit des personnes âgées de 30 à 79 ans dont la mère est encore en vie. Nous avons donc besoin de deux variables supplémentaire : l’âge des personnes pour exclure les moins de 30 ans (MA_AGEM_rec), ainsi que la variable indiquant si la mère est en vie ou non (PA_MEREBV_rec)
- Enfin, bien que celle-ci ne soit pas directement visible sur le graphique, il ne faut pas oublier la variable de pondération : poids12
Le nom de chaque variable est indiqué dans le dictionnaire des codes du fichier pédagogique.
Sélectionner les variables nécessaires
Nous allons créer une nouvelle table, nommée erfi, qui contiendra uniquement ces variables. Pour cela, nous utilisons la fonction select, issue du package dplyr (inclus dans le tidyverse).
erfi <- select(ERFI1_FPA, PF_AGEDEPFOY_rec, PA_FQAVM_rec, MA_AGEM_rec, PA_MEREBV_rec, poids12)Dans les arguments de la fonction select, on indique en premier lieu le nom de la table dans laquelle se trouvent les variables à sélectionner (ici ERFI1_FPA), puis le nom de chacune des variables à sélectionner, séparés par une virgule.
On assigne le résultat à un objet nommé erfi.
Exploration des variables d’intérêt
Commençons par observer la répartition des individus selon les différentes modalités des deux variables d’intérêt, l’âge au départ du foyer parental et la fréquence des visites à la mère. On va pour cela effectuer un tri à plat sur ces deux variables.
On utilise pour cela la fonction table. Son argument principal est la variable sur laquelle on souhaite réaliser le tri à plat. L’argument useNA = "always" sert à préciser que l’on souhaite que le résultat tienne compte des valeurs manquantes (par défaut, elles sont exclues).
Pour l’âge au départ du foyer parental :
table(erfi$PF_AGEDEPFOY_rec, useNA = "always")
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
63 13 20 13 17 17 18 14 21 18 30 37 47 63 158 173
16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 <NA>
265 458 1228 1134 1312 1007 805 708 507 362 248 154 118 89 380 582 - Il y a 582 valeurs manquantes. Comment expliquer que ce nombre soit aussi important ?
- Regardons le questionnaire : avant la question sur l’âge au départ du foyer parental (p. 85), il est précisé que la question n’est posée que si le répondant ne vit avec aucun de ses deux parents. Autrement dit, tous les individus ne sont pas concernés par cette question, ce qui explique le grand nombre de valeurs manquantes.
- Il n’y a pas d’âge supérieur à 30. Cela signifie-t-il que personne n’a quitté le foyer parental après 30 ans ?
- Cette fois-ci, c’est vers le dictionnaire des codes qu’il faut se tourner. Celui-ci nous indique que la modalité “30” correspond en réalité à “30 ans et plus”. Il y a donc bien des individus qui ont quitté le foyer parental à plus de 30 ans, mais ils ne sont pas distingués. On fait de même pour la fréquence de visite à la mère :
table(erfi$PA_FQAVM_rec, useNA = "always")
0 1 2 3 9 <NA>
377 2773 2597 66 8 4258 Là encore, le grand nombre de valeurs manquantes s’explique par le fait que la question sur la fréquence des visites à la mère n’est posée qu’aux personnes dont la mère est vivante, et qui ne vivent pas avec elle. On peut le voir dans le module Parents et foyer parental du questionnaire (p. 70 à 78).
Filtrer la population concernée
Nous avons pu identifier à l’étape précédente qu’un grand nombre de personnes n’ont pas répondu aux questions étudiées ici car non concernées. De plus, le champ du graphique précise que l’étude porte sur les personnes âgées de 30 à 79 ans, dont la mère est encore en vie. Or, les personnes enquêtées pour l’enquête ERFI-1 sont âgées de 18 à 79 ans, que leur mère soit vivante ou non.
Il faut donc appliquer un filtre sur la base de données initiale, afin de ne conserver que les individus concernés par notre analyse.
On repart de la base erfi créée à l’étape précédente. Nous allons cette fois utiliser une autre fonction issue du package dplyr, filter.
erfi <- filter(erfi, MA_AGEM_rec >= 30 & PA_MEREBV_rec == 1)Les arguments de la fonction filter sont en premier lieu le nom de la table sur laquelle on veut appliquer le filtre (ici, erfi), puis les conditions sur lesquelles on doit filtrer cette table. Ici, on souhaite conserver les personnes qui sont âgées d’au moins 30 ans (MA_AGEM_rec >= 30) ET (&) dont la mère est en vie (PA_MEREBV_rec == 1).
On assigne le résultat à l’objet erfi. Le nombre de lignes est désormais réduit : 4563 au lieu de 10079 précédemment, car n’ont été conservées que les lignes correspondant aux individus remplissant les deux conditions du filtre.
Note
Lorsqu’on assigne un résultat à un objet déjà existant (comme c’est le cas ici avec erfi), on écrase ce qu’il contenait précédemment, sans possibilité de retour en arrière. Si l’on constate une erreur dans l’application du filtre, il faudra relancer la ligne de commande précédente (select) afin de retrouver la table erfi initiale. On aurait pu assigner le résultat à un nouvel objet en choisissant un nom qui n’a pas déjà été utilisé (par exemple erfi_filtre), pour ne pas prendre de risque.
Données manquantes
La population étant maintenant réduite à celle concernée par l’analyse, procédons à nouveau à un tri à plat sur les variables d’intérêt, pour vérifier s’il reste des données manquantes.
table(erfi$PF_AGEDEPFOY_rec, useNA = "always")
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
23 1 5 6 4 4 10 3 8 7 12 10 12 17 53 65
16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 <NA>
123 220 615 552 636 500 409 348 268 193 119 76 66 51 143 4 table(erfi$PA_FQAVM_rec, useNA = "always")
0 1 2 3 9 <NA>
314 2220 1969 52 8 0 Il n’y a pas de données manquantes pour la fréquence de visite à la mère, en revanche, il en reste 4 pour l’âge au départ du foyer parental. Ce nombre étant très faible, on peut se contenter d’exclure les individus correspondant de la base de données pour le reste de l’analyse.
Pour cela, nous allons procéder à un nouveau filtre.
erfi <- filter(erfi, complete.cases(PF_AGEDEPFOY_rec))On utilise à nouveau la fonction filter, avec comme premier argument la table que l’on souhaite filtrer (toujours erfi, dans notre cas). Puis, le second argument complete.cases(PF_AGEDEPFOY_rec) indique que l’on souhaite conserver uniquement les lignes qui comportent une valeur pour la variable PF_AGEDEPFOY_rec.
On assigne le résultat à l’objet erfi déjà existant, qui n’a désormais plus de 4559 lignes, les 4 individus pour lesquels il manque l’âge au départ du foyer parental ayant été exclus par le filtre.
Note
Dans notre cas, les données manquantes étant très peu nombreuses, on peut se contenter de supprimer les individus concernés. Cependant, lorsque ces données concernent un nombre important d’individus, il peut être important de les analyer pour comprendre d’où elles proviennent, et si les non-répondants ont un profil particulier.
Quelques pistes d’analyse des données manquantes sont explorées dans cet article.
Recoder les variables
Créer des classes d’âge au départ du foyer parental
Pour réaliser le tableau et le graphique souhaités, nous avons besoin de découper la variable d’âge au départ du foyer parental (variable quantitative continue, stockée au format numeric dans la base de données), en classes, comme sur l’axe horizontal du graphique.
On utilise pour cela l’interface icut du package questionr.
icut()Dans l’interface qui s’ouvre suite au lancement de la commande icut(), il y a trois informations à renseigner :
- A : le nom de la table dans laquelle se trouve la variable à découper ;
- B : le nom de la variable à découper ;
- C : le nom que l’on souhaite donner à la variable qui contiendra le découpage réalisé. Par défaut, l’interface propose de rajouter le suffixe “_rec” au nom de la variable d’origine, mais l’utilisateur est libre de choisir le nom de variable qu’il souhaite. Ici, on a choisi AGE_DEP.
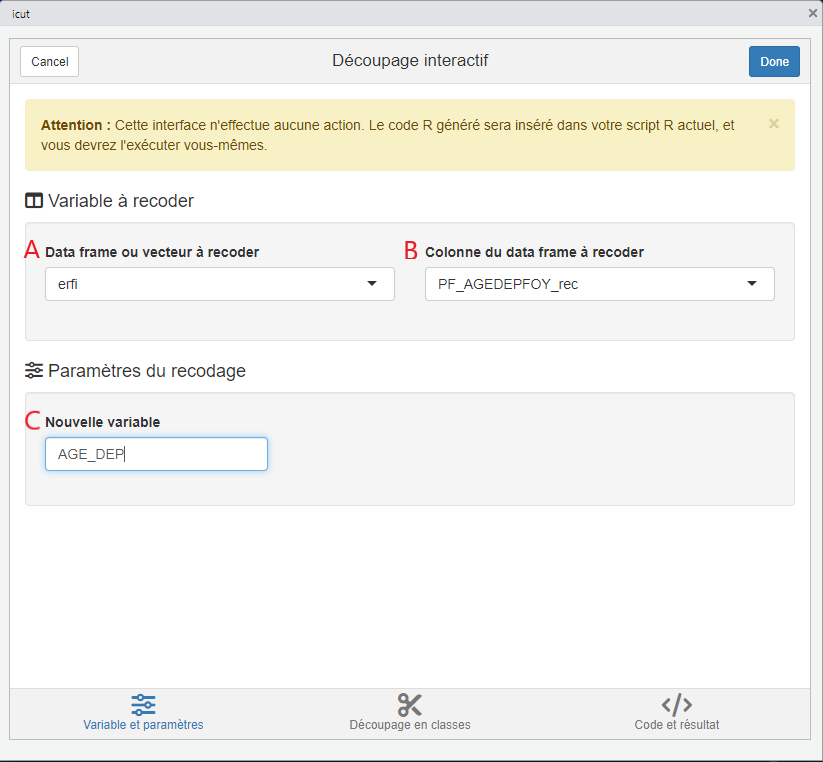
En cliquant sur Découpage en classes, on arrive sur l’interface qui permet de déterminer les classes souhaitées.
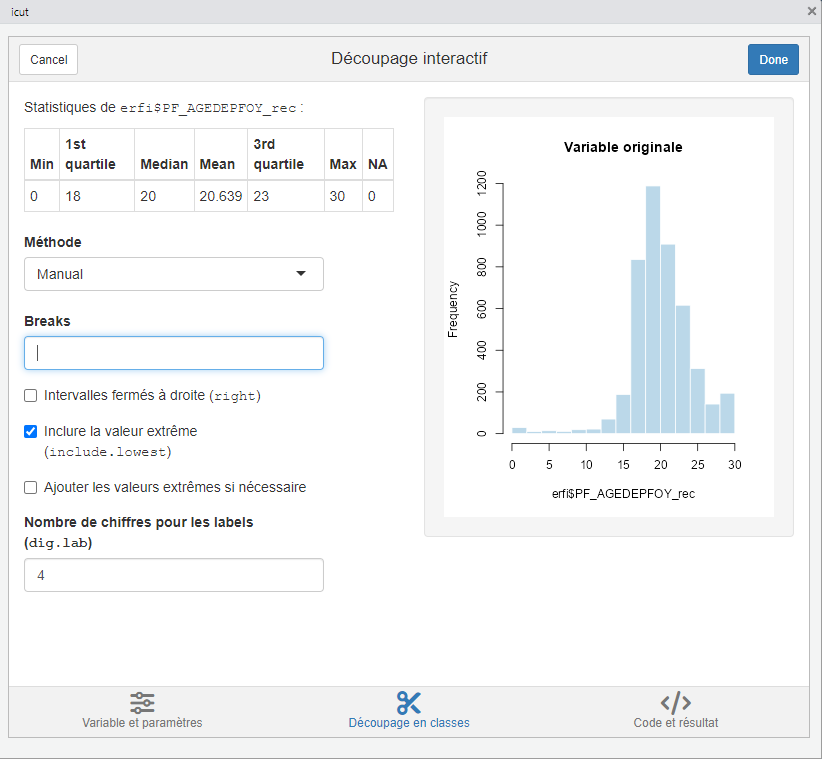
La liste déroulante Méthode propose toute une série de méthodes automatiques de découpage d’une variable quantitative selon différents procédés statistiques. Nous utiliserons le mode manuel (Manual), qui propose à l’utilisateur de définir des propres bornes de classes (séparées par une virgule), à définir dans Breaks.
Note
Par défaut, les intervalles sont ouverts à droite (exemple : [0;20[ ). Ainsi, si l’on renseigne : 0,10,20 comme bornes de classe, les intervalles créés seront : [0;10[ ; [10;20[. On peut changer cela en cochant la case “Intervalles fermés à droite”.
En cliquant sur Code et résultat, on peut visualiser un tri à plat de la variable une fois découpée en classes. Cela permet notamment de voir si les intervalles créés correspondent bien à ceux souhaités, et si la répartition des individus dans les différentes classes est satisfaisante. Si la répartition est très déséquilibrée et que certaines classes ne contiennent que très peu d’individus, cela signifie que le découpage n’est pas le plus approprié.
Si l’on souhaite modifier le découpage, il suffit de cliquer à nouveau sur Découpage en classes pour revenir à l’interface précédente.
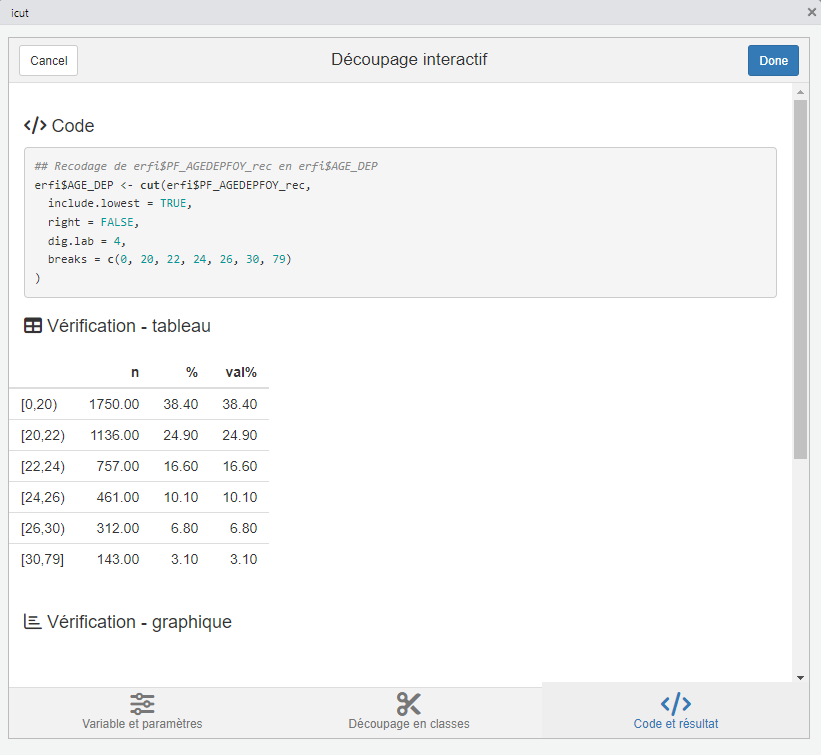
Une fois satisfait du découpage réalisé, on peut cliquer sur le bouton Done en haut à droite. L’interface se ferme et les lignes de code permettant d’exécuter le découpage choisi s’insèrent dans le script.
## Recodage de erfi$PF_AGEDEPFOY_rec en erfi$AGE_DEP
erfi$AGE_DEP <- cut(erfi$PF_AGEDEPFOY_rec,
include.lowest = TRUE,
right = FALSE,
dig.lab = 4,
breaks = c(0, 20, 22, 24, 26, 30, 79)
)
Avertissement
L’interface icut ne fait que génèrer le code nécessaire au découpage de la variable, mais elle ne l’exécute pas. Actuellement, la variable AGE_DEP contenant l’âge au départ du foyer, regroupé en classes, n’existe pas encore. Pour la créer, il faut exécuter les lignes de codes insérées dans le script par icut, en les sélectionnant puis cliquant sur  , ou simultanément sur les touches clavier Ctrl + Enter pour Windows / Cmd + Enter pour Mac. On peut alors constater dans l’environnement que la table erfi contient désormais 6 variables et non plus 5. On peut également réaliser un tri à plat sur la nouvelle variable AGE_DEP pour s’assurer que sa création s’est bien déroulée.
, ou simultanément sur les touches clavier Ctrl + Enter pour Windows / Cmd + Enter pour Mac. On peut alors constater dans l’environnement que la table erfi contient désormais 6 variables et non plus 5. On peut également réaliser un tri à plat sur la nouvelle variable AGE_DEP pour s’assurer que sa création s’est bien déroulée.
table(erfi$AGE_DEP, useNA = "always")
[0,20) [20,22) [22,24) [24,26) [26,30) [30,79] <NA>
1750 1136 757 461 312 143 0 Recodage de la fréquence de visite à la mère
La variable de fréquence de visite à la mère présente cinq modalités, d’après le dictionnaire des codes : “Jamais” ; “moins d’une fois par an” ; “Moins d’une fois par semaine” ; “Au moins une fois par semaine” ; “Plusieurs fois par jour” ; “Ne sait pas”. Or, nous souhaitons seulement distinguer les personnes qui voient leur mère au moins une fois par semaine de ceux qui la voient moins fréquemment. Il nous faut donc recoder cette variable pour ne garder que deux modalités : “oui” ; “non”.
Pour cela, on utilise une autre interface issue du package questionr, irec, destinée au recodage des variables qualitatives.
irec()Cette interface fonctionne de manière très similaire à celle de icut. Dans la première fenêtre, on renseigne la variable que l’on souhaite recoder et la méthode que l’on souhaite employer pour cela :
- A : le nom de la table dans laquelle se trouve la variable à recoder ;
- B : le nom de la variable à recoder ;
- C : le nom que l’on souhaite donner à la variable créée à l’issue du recodage. Par défaut, l’interface propose de rajouter le suffixe “_rec” au nom de la variable d’origine, mais l’utilisateur est libre de choisir le nom de variable qu’il souhaite. Ici, on a choisi FREQ_MERE ;
- D : la méthode que l’on souhaite employer pour le recodage. Ici on a choisi Character - minimal, qui est la méthode la plus simple ;
- E : la classe de l’objet contenant la nouvelle variable (FREQ_MERE). Etant donné qu’il s’agit d’une variable qualitative, on peut choisir Character ou Factor. Ici, on a choisi Character par souci de simplicité pour la formation.
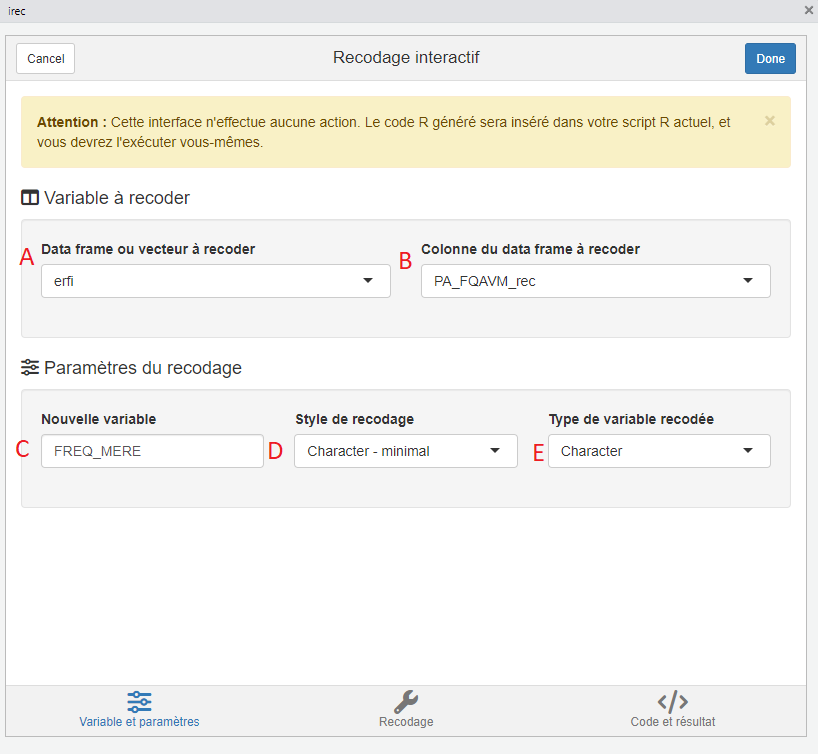
En cliquant sur Recodage, on arrive sur l’interface qui permet d’indiquer comment on souhaite recoder les modalités existantes de la variable.
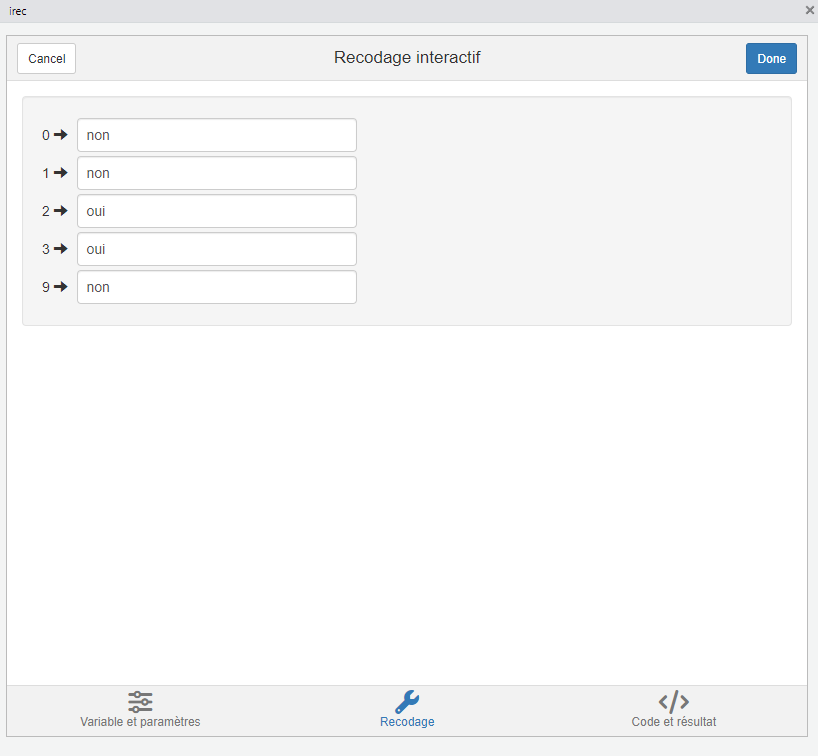
En face de chacune des modalités existantes, on inscrit la valeur que cette modalité devra prendre dans le nouveau regroupement.
- Les modalités 0 et 1 (qui signifient respectivement “Jamais, moins d’une fois par an” et “Moins d’une fois par semaine” d’après le dictionnaire des codes) correspondent à des personnes qui voient leur mère moins d’une fois par semaine : on va donc les recoder en “non”.
- Les modalités 2 et 3 (respectivement “Au moins une fois par semaine” et “Plusieurs fois par jour” d’après le dictionnaire des codes) correspondent à des personnes qui voient leur mère au moins une fois par semaine : on va donc les recoder en “oui”.
- Que faire de la modalité 9 (“Ne sait pas”) ?
- De manière générale, la modalité “Ne sait pas” est laissée comme telle lors des opérations de recodage, sauf s’il y a une raison pertinente de regrouper ces individus avec une modalité particulière. Ici, si une personne a répondu ne pas savoir à quelle fréquence elle voit sa mère, on peut supposer que les visites sont très irrégulières, donc que la personne voit sa mère moins souvent qu’une fois par semaine. Il est donc cohérent de recoder “Ne sait pas” en “non”.
Attention à la casse et aux fautes de frappe lorsque l’on renseigne les nouvelles modalités. Par exemple, si l’on inscrit “non” en face de “0” et “Non” en face de “1”, R considère qu’il s’agit de deux modalités différentes, et la nouvelle variable créée suite au recodage aura alors deux modalités “non” différentes, l’une orthographiée sans majuscule et l’autre avec une majuscule. Les modalités “0” et “1” de la variable d’origine n’auront pas été regroupées. Pour éviter cela, le plus simple est d’inscrire une seule fois chaque nouvelle modalité et de faire des copier-coller les fois suivantes.
En cliquant sur Code et résultats, on peut visualiser un tableau croisant l’ancienne et la nouvelle variable, pour voir si le recodage effectué correspond bien à celui souhaité. Si ce n’est pas le cas, on peut revenir à l’interface précédente en cliquant à nouveau sur Recodage.
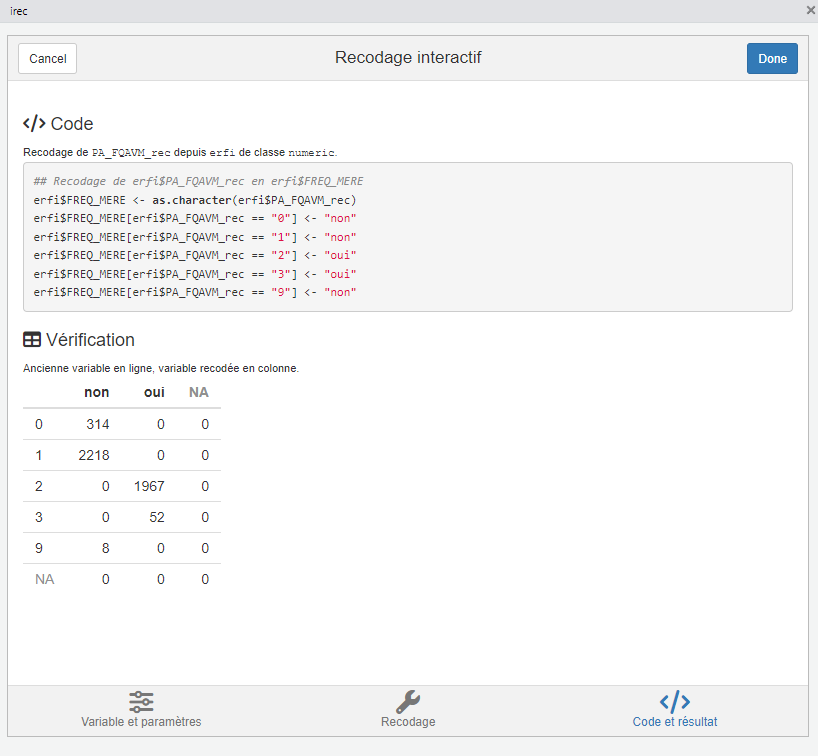
Une fois satisfait du recodage, on peut cliquer sur le bouton Done en haut à droite. Tout comme avec l’interface icut, le code permettant de réaliser le recodage est alors généré par l’interface et inséré dans le script, mais il n’est pas exécuté. C’est à l’utilisateur de le faire en sélectionnant les lignes générées et en cliquant sur ou simultanément sur touches clavier Ctrl + Enter pour Windows / Cmd + Enter pour Mac.
## Recodage de erfi$PA_FQAVM_rec en erfi$FREQ_MERE
erfi$FREQ_MERE <- as.character(erfi$PA_FQAVM_rec)
erfi$FREQ_MERE[erfi$PA_FQAVM_rec == "0"] <- "non"
erfi$FREQ_MERE[erfi$PA_FQAVM_rec == "1"] <- "non"
erfi$FREQ_MERE[erfi$PA_FQAVM_rec == "2"] <- "oui"
erfi$FREQ_MERE[erfi$PA_FQAVM_rec == "3"] <- "oui"
erfi$FREQ_MERE[erfi$PA_FQAVM_rec == "9"] <- "non"La table erfi contient désormais 7 variables. On peut vérifier que le recodage s’est bien passé en effectuant un tri à plat sur la nouvelle variable FREQ_MERE.
table(erfi$FREQ_MERE, useNA = "always")
non oui <NA>
2540 2019 0 Tris à plat, tri croisé
Les tableaux que nous avons réalisés jusqu’à maintenant sont des tableaux d’effectifs bruts, sans pondération. Ils servent à vérifier la structure des données, mais pas à l’analyse.
Tri à plat sur l’âge au départ du foyer parental
Pour connaître la répartition des individus selon leur âge au départ du foyer parental, on utilise la fonction wtd.table du package questionr. Celle-ci fonctionne de manière très similaire à la fonction table utilisée précédemment, mais elle permet en plus de prendre en compte une variable de pondération, avec l’argument weights.
wtd.table(erfi$AGE_DEP, weights = erfi$poids12) [0,20) [20,22) [22,24) [24,26) [26,30) [30,79]
7313804.8 4773950.4 3161785.6 1977938.9 1407880.1 616330.7 On obtient un tableau d’effectifs pondérés. Si l’on souhaite obtenir la répartition des individus sous forme de pourcentages (plus lisible, et préférable dès lors que l’on veut réaliser des comparaisons), il faut utiliser la fonction proportions.
On peut utiliser l’opérateur pipe (%>%) pour appliquer cette fonction directement sur le tableau précédemment réalisé.
wtd.table(erfi$AGE_DEP, weights = erfi$poids12) %>% #tableau d'effectifs
proportions() #calcule les pourcentages [0,20) [20,22) [22,24) [24,26) [26,30) [30,79]
0.37990455 0.24797565 0.16423418 0.10274105 0.07313021 0.03201437 Tri à plat sur la fréquence de visite à la mère
On répète les mêmes opérations pour obtenir la répartition des individus selon la fréquence de visite à leur mère.
wtd.table(erfi$FREQ_MERE, weights = erfi$poids12) %>%
proportions() non oui
0.5664051 0.4335949 On peut observer que 43 % des individus déclarent voir leur mère au moins une fois par semaine. Mais cette proportion varie-t-elle selon l’âge auquel on a quitté le foyer familial ? Pour le savoir, il faut procéder à un tri croisé entre les deux variables.
Tri croisé
Comme pour le tri à plat, on utilise la fonction wtd.table du package questionr, mais elle prend cette fois-ci trois arguments :
- La variable à représenter sur les lignes du tableau croisé ;
- La variable à représenter sur les colonnes du tableau croisé ;
- La variable de pondération, avec l’argument weights
wtd.table(erfi$AGE_DEP, erfi$FREQ_MERE, weights = erfi$poids12) non oui
[0,20) 4681550.3 2632254.5
[20,22) 2640812.5 2133137.8
[22,24) 1718352.7 1443432.9
[24,26) 982355.7 995583.2
[26,30) 632651.4 775228.7
[30,79] 248532.1 367798.5On obtient un tableau croisé d’effectifs pondérés, avec en lignes l’âge au départ du foyer parental, et en colonnes la fréquence de visite à la mère.
Pour calculer les valeurs en pourcentage, il faut en premier lieu se demander si l’on souhaite obtenir des pourcentages en ligne ou des pourcentages en colonne. Cela dépend de la position des variables dans le tableau. Ici, on souhaite comparer la répartition des fréquences de visite à la mère en fonction de l’âge au départ du foyer parental. On veut donc pouvoir comparer les différentes tranches d’âges entre elles. Celles-ci étant présentées en ligne dans le tableau, il nous faut donc calculer les pourcentages en ligne.
Pour cela, on va appliquer la fonction lprop au tableau précédemment réalisé.
wtd.table(erfi$AGE_DEP, erfi$FREQ_MERE, weights = erfi$poids12) %>%
lprop() non oui Total
[0,20) 64.0 36.0 100.0
[20,22) 55.3 44.7 100.0
[22,24) 54.3 45.7 100.0
[24,26) 49.7 50.3 100.0
[26,30) 44.9 55.1 100.0
[30,79] 40.3 59.7 100.0
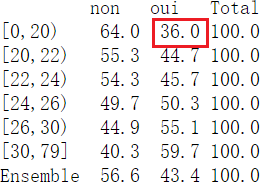
Ensemble 56.6 43.4 100.0Ainsi, presque 60 % des personnes ayant quitté le foyer parental à 30 ans ou plus voient leur mère au moins une fois par semaine, contre seulement 36 % des personnes qui l’ont quitté avant 20 ans. La fréquence de visite à la mère n’est donc pas indépendante de l’âge au départ du foyer parental.
Pourcentages en ligne, pourcentages en colonne : éléments de lecture
Dans le tableau ci-dessous, qui présente des pourcentages en ligne, la valeur encadrée se lit : “parmi les personnes qui ont quitté le foyer parental avant 20 ans, 36 % voient leur mère au moins une fois par semaine.”
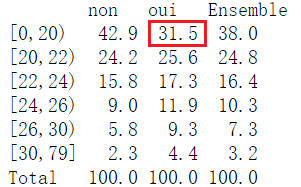
Dans le second tableau, réalisé à partir des mêmes données, mais qui les présente sous forme de pourcentages en colonnes (fonction cprop() dans R), la valeur encadrée se lit : “parmi les personnes qui voient leur mère au moins une fois par semaine, 31,5 % ont quitté le foyer parental avant l’âge de 20 ans.”
Représentation graphique avec Esquisse
Préparation des données
Pour représenter cette même information graphiquement, il est nécessaire d’effectuer un travail préalable de préparation des données.
Dans un premier temps, nous allons stocker le tableau croisé réalisé précédemment (dont le résultat s’est affiché dans la console) dans notre environnement R, afin de pouvoir l’utiliser pour la réalisation du graphique. Pour cela, on relance les mêmes lignes de code que précédemment, mais en assignant le résultat à un objet, nommé TCROIS.
TCROIS <- wtd.table(erfi$AGE_DEP, erfi$FREQ_MERE, weights = erfi$poids12) %>%
lprop()Cette fois-ci, la tableau ne s’affiche pas dans la console, en revanche, un nouvel objet, TCROIS, est apparu dans notre environnement. En utilisant la fonction class, nous pouvons voir que celui-ci est de type table.
class(TCROIS)[1] "proptab" "table" Pour pouvoir utiliser les fonctions permettant la réalisation des graphiques, il nous faut changer le format de l’objet contenant les données en data.frame, car ces fonctions ne s’appliquent que sur ce type d’objet.
On utilise pour cela la fonction as.data.frame, et on assigne le résultat à un nouvel objet que l’on nomme erfi_mere.
erfi_mere <- as.data.frame(TCROIS) Ce nouvel objet erfi_mere contient les valeurs du tableau croisé, mais sous un format différent.
- La colonne Var1 contient les tranches d’âge au départ du foyer (affichées sur les lignes du tableau croisé) ;
- La colonne Var2 contient les fréquences de visite à la mère (affichées sur les colonnes du tableau croisé) ;
- La colonne Freq contient les pourcentages correspondant à chaque intersection, contenus dans les cases du tableau croisé.
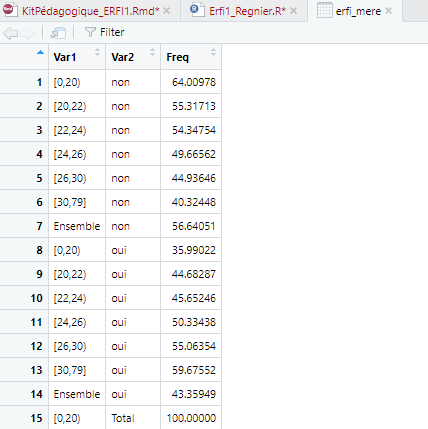
Les noms Var1 et Var2 n’étant pas du tout explicites sur le contenu des variables que contiennent ces colonnes, il est préférable de les renommer. On fait pour cela appel à la fonction rename du package dplyr. Ses arguments se présentent sous la forme suivante : nouveau_nom = ancien_nom. On peut renommer plusieurs variables avec la même ligne de code, en les séparant par une virgule.
erfi_mere <- as.data.frame(TCROIS) %>% #on transforme T en data frame
rename(age = Var1, visite_mere = Var2) #on renomme certaines colonnes pour que les noms soient plus explicitesEnfin, on ne souhaite pas représenter les marges du tableau croisé (c’est-à-dire la ligne “Ensemble” et la colonne “Total”) sur le graphique. Les données correspondant à cette ligne et à cette colonne ne doivent donc pas être présentes dans le tableau de données.
On va utiliser la fonction filter du package dplyr pour ne conserver que les âges différents de “Ensemble”, et les fréquences de visite à la mère différentes de “Total”.
erfi_mere <- as.data.frame(TCROIS) %>% #on transforme T en data frame
rename(age = Var1, visite_mere = Var2) %>% #on renomme certaines colonnes pour que les noms soient plus explicites
filter(age != "Ensemble" & visite_mere != "Total") #on filtre pour enlever les marges du tableau croiséLes données sont désormais prêtes pour être utilisées avec les fonctions de représentation graphique.
Réalisation du graphique
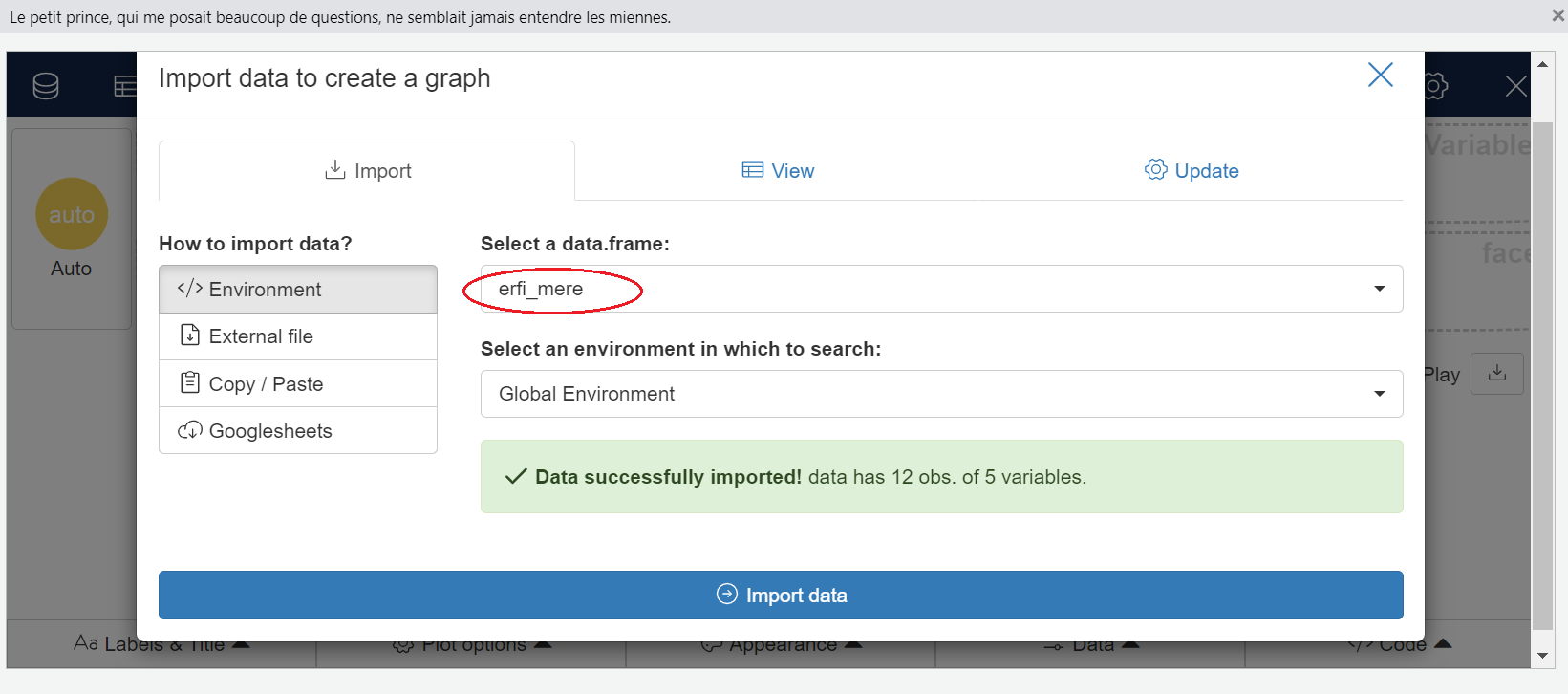
Pour réaliser le graphique, on utilise l’interface equisser du package esquisse.
esquisser()Dans l’interface qui s’ouvre suite au lancement de la commande esquisser(), on choisit dans la première liste déroulante la table dans laquelle se trouve les données qui vont servir à la construction du graphique. Ici, il s’agit de la table erfi_mere que l’on vient de créér lors de l’étape de préparation des données.
On clique ensuite sur Import Data pour importer le jeu de données.
On construit ensuite le graphique en faisant glisser les variables vers les champs correspondants :
- X : variable à placer en abscisses (ici, il s’agit de l’âge au départ du foyer, age) ;
- Y : valeurs de la variable représentée en ordonnées (ici, il s’agit de la fréquence de visite à la mère, en pourcentage, Freq) ;
- fill : modalités de la variable représentée en ordonnées, pour les distinguer au sein des barres par différentes couleurs (ici, il s’agit de la variable visite_mere)
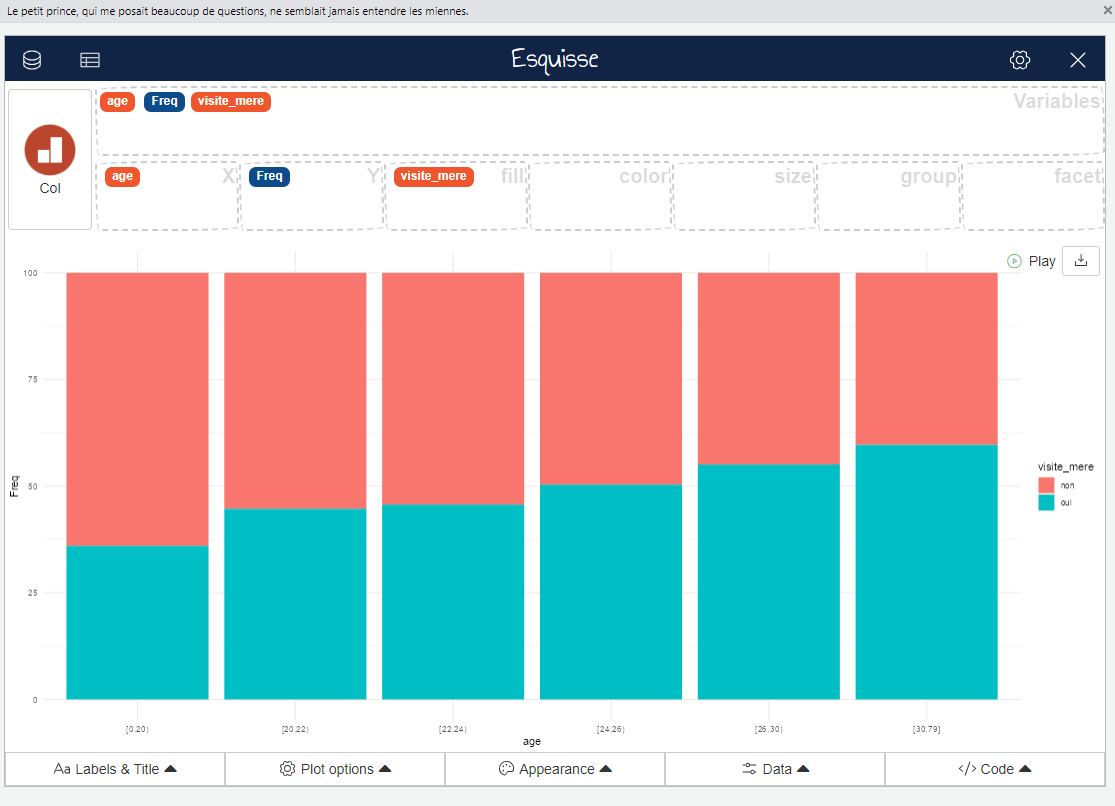
L’interface choisit automatiquement le type de graphique le plus adapté en fonction des données sélectionnées. Si cela ne correspond pas au type de graphique que l’on souhaite, il est possible de le modifier en cliquant sur le bouton Col en haut à gauche. Les différents types de graphique qu’il est possible de réaliser avec les données sélectionnées sont alors proposés.
Les onglets en bas offrent différentes options pour adapter et mettre en forme le graphique obtenu :
Labels & Title : Ajouter un titre, un sous-titre, une source, changer les noms des axes et le titre de la légende. En cliquant sur le symbole + à côté de chaque option, on peut également modifier sa mise en forme (police, taille, alignement…)
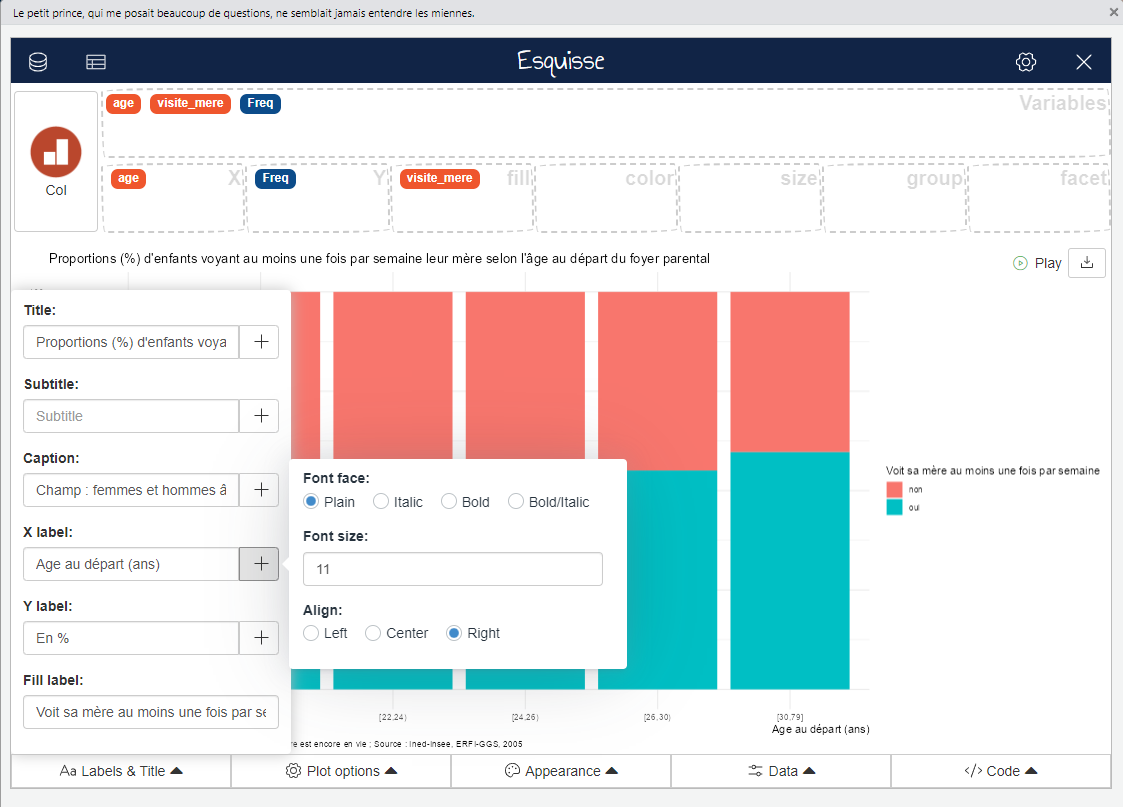
Plot options : Modifier les options du graphique, notamment les limites des axes
Appearance : Modifier les couleurs et le thème du graphique
Data : Appliquer des filtres sur les données représentées (par exemple, ne pas représenter les valeurs extrêmes, ou certaines modalités)
Code : Visualiser le code permettant de générer le graphique.
Il n’est pas possible d’exporter le graphique directement depuis l’interface esquisser. Celui-ci disparaitra sitôt l’interface fermée. Pour le conserver, il est nécessaire de visualiser le code permettant de générer le graphique et de le copier/coller dans son script, puis de l’exécuter. Le graphique ainsi généré apparaît alors dans l’onglet Plots du quadrant inférieur droit de RStudio, où il est possible de l’exporter avec le bouton 
Note
Une fois le code permettant de générer le graphique copié/collé dans le script, on peut le modifier pour faire appel à des options non disponibles dans l’interface esquisser (exemples : changer les labels des modalités sur l’axe des abscisses, placer la légende en bas plutôt qu’à droite, etc.). Une documentation complète du package ggplot2, sur lequel s’appuie esquisse pour la réalisation des graphiques, est disponible ici.
ggplot(erfi_mere) +
aes(x = age, y = Freq, fill = visite_mere) +
geom_col() +
scale_fill_manual(values = c(non = "#A50026",
oui = "#006837")) +
labs(x = "Age au départ (ans)", y = "En %", title = "Proportion (%) d'enfants voyant leur mère\nau moins une fois par semaine, selon l'âge au départ du foyer parental",
caption = "Champ : femmes et hommes âgés de 30 à 79 ans, dont la mère est encore en vie ;\nSource : Ined-Insee, ERFI-GGS, 2005",
fill = "Voit sa mère au moins\nune fois par semaine") +
theme_classic() +
theme(plot.title = element_text(face = "bold.italic", size = 12,
hjust = 0.5), plot.caption = element_text(face = "italic", hjust = 0), axis.title.y = element_text(hjust = 1),
axis.title.x = element_text(hjust = 1))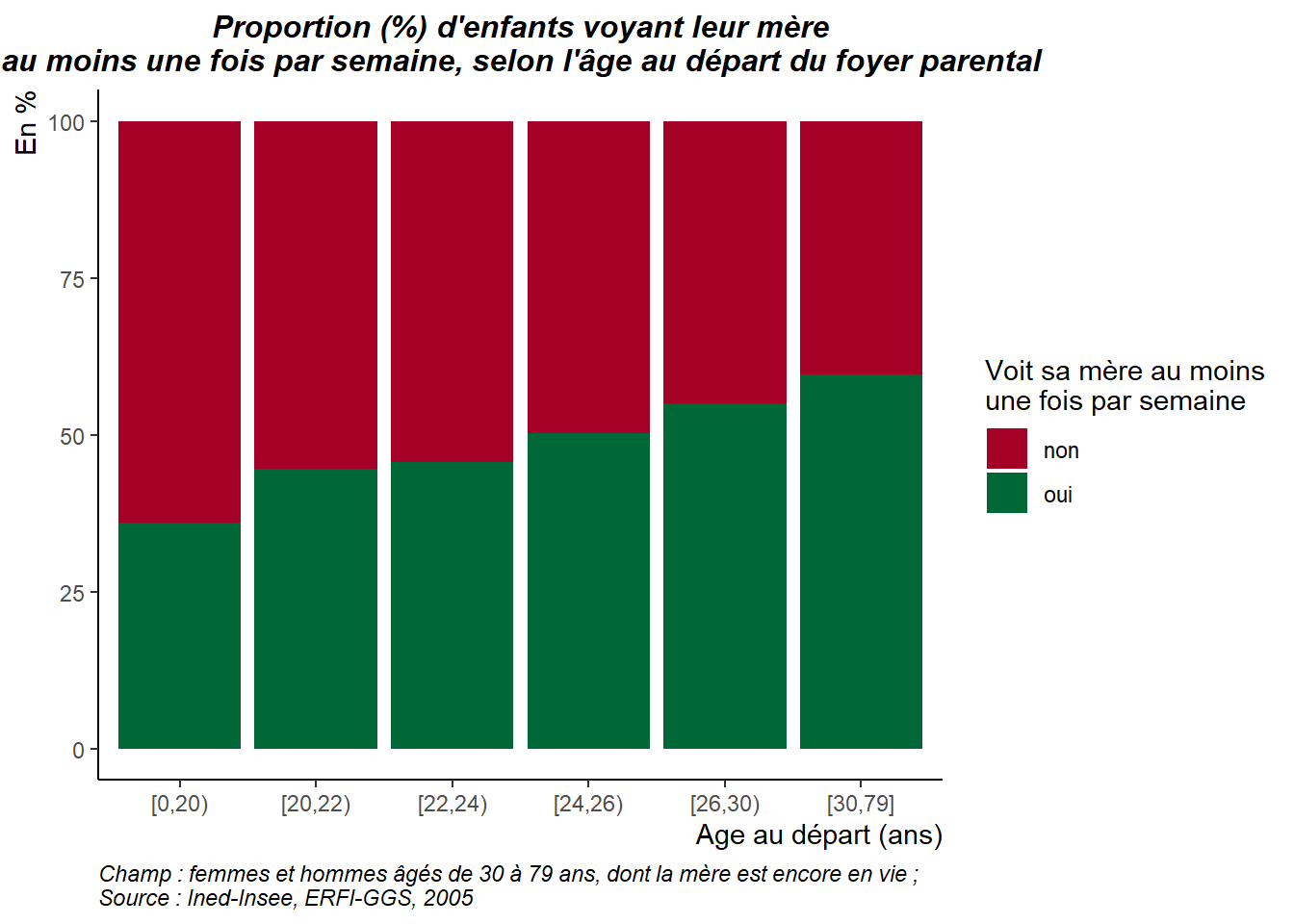
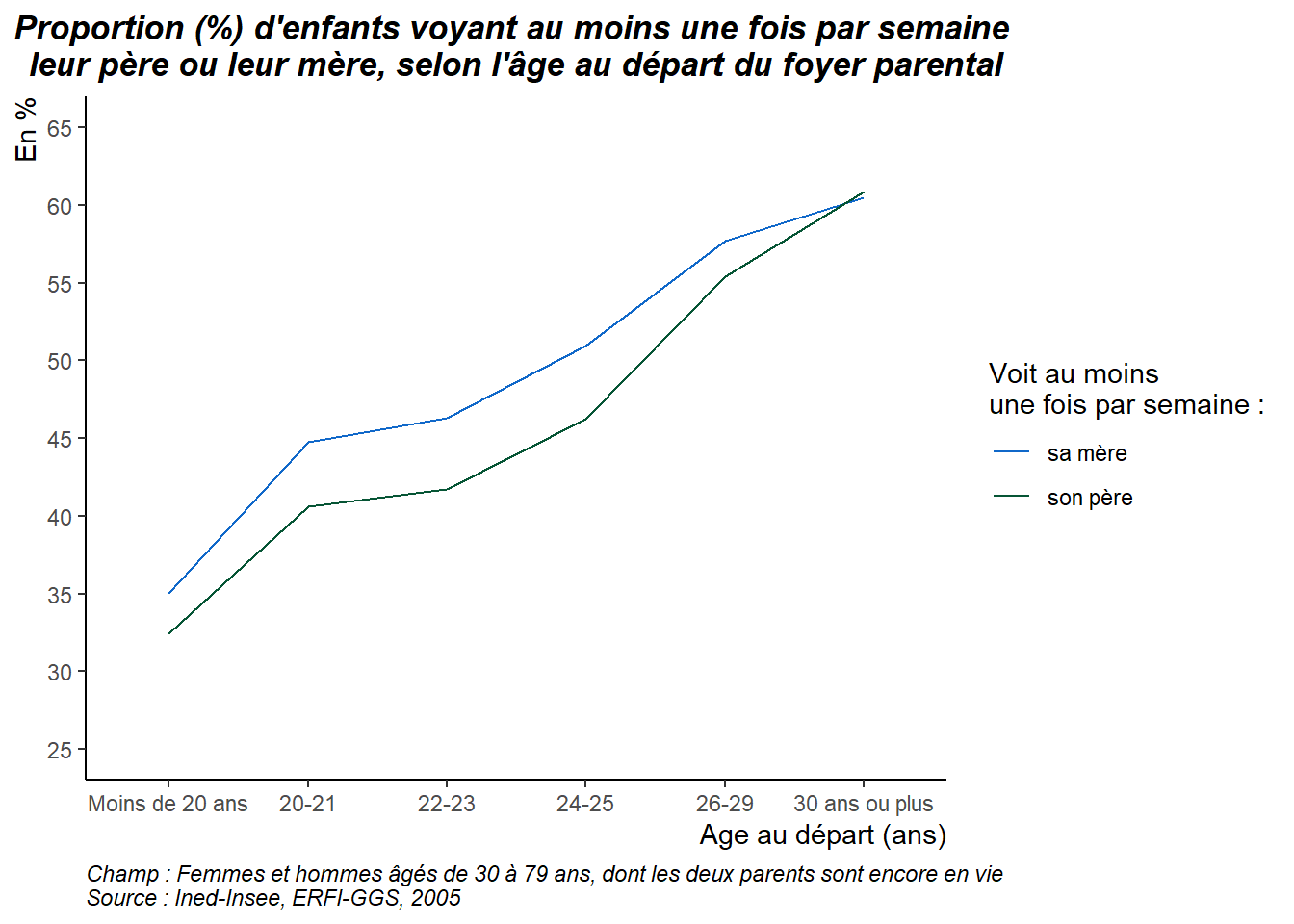
Pour reproduire à l’identique la figure 1 de l’article de Population & Sociétés, on peut exécuter le code ci-dessous, qui reprend en grande partie les traitements réalisés au cours de cette formation. On y ajoute les traitements nécessaires au calcul des proportions de personnes qui voient au moins une semaine leur père, et quelques modifications sont apportés au code permettant la réalisation du graphique afin de produire des courbes (type de graphique impossible à réaliser via l’interface esquisser sur ce type de données).
#sélection des variables utiles et des individus concernés
erfi <- select(ERFI1_FPA, MA_AGEM_rec, PA_FQAVM_rec, PF_AGEDEPFOY_rec, PA_MEREBV_rec, PB_PEREBV_rec, PB_FQAVP_rec, poids12)
erfi <- filter(erfi, MA_AGEM_rec >= 30 & PA_MEREBV_rec == 1 & PB_PEREBV_rec == 1)
erfi <- filter(erfi, complete.cases(PF_AGEDEPFOY_rec))
#recodage âge au départ du foyer
erfi$AGE_DEP <- cut(erfi$PF_AGEDEPFOY_rec,
include.lowest = TRUE,
right = FALSE,
dig.lab = 4,
breaks = c(0, 20, 22, 24, 26, 30, 79)
)
#recodage fréquence des visites aux parents
erfi$FREQ_MERE <- as.character(erfi$PA_FQAVM_rec)
erfi$FREQ_MERE[erfi$PA_FQAVM_rec == "0"] <- "non"
erfi$FREQ_MERE[erfi$PA_FQAVM_rec == "1"] <- "non"
erfi$FREQ_MERE[erfi$PA_FQAVM_rec == "2"] <- "oui"
erfi$FREQ_MERE[erfi$PA_FQAVM_rec == "3"] <- "oui"
erfi$FREQ_MERE[erfi$PA_FQAVM_rec == "9"] <- "non"
erfi$FREQ_PERE <- as.character(erfi$PB_FQAVP_rec)
erfi$FREQ_PERE[erfi$PB_FQAVP_rec == "0"] <- "non"
erfi$FREQ_PERE[erfi$PB_FQAVP_rec == "1"] <- "non"
erfi$FREQ_PERE[erfi$PB_FQAVP_rec == "2"] <- "oui"
erfi$FREQ_PERE[erfi$PB_FQAVP_rec == "3"] <- "oui"
erfi$FREQ_PERE[erfi$PB_FQAVP_rec == "9"] <- "non"
#calcul des % pour les visites à la mère
TAB_MERE <- wtd.table(erfi$AGE_DEP, erfi$FREQ_MERE, weights = erfi$poids12) %>%
lprop() %>% as.data.frame() %>%
rename(age = Var1, visite = Var2) %>%
filter(age != "Ensemble" & visite == "oui") %>% #on veut représenter sur le graphique seulement la part de personnes qui voient leur mère une fois par semaine, donc on ne garde que les "oui"
mutate(parent = "mere") #on crée une nouvelle variable indiquant le parent concerné
#on fait de même pour les visites au père
TAB_PERE <- wtd.table(erfi$AGE_DEP, erfi$FREQ_PERE, weights = erfi$poids12) %>%
lprop() %>% as.data.frame() %>%
rename(age = Var1, visite = Var2) %>%
filter(age != "Ensemble" & visite == "oui") %>%
mutate(parent = "pere")
#on rassemble les deux tableaux en un seul
DATA_GRAPH <- rbind(TAB_MERE, TAB_PERE)
#Représentation graphique
ggplot(DATA_GRAPH, aes(age, Freq, color = parent, group = parent)) +
geom_line() +
scale_x_discrete(labels = c("Moins de 20 ans", "20-21", "22-23", "24-25", "26-29", "30 ans ou plus")) + #mettre des labels sur l'axe des abscisses
scale_y_continuous(limits = c(25,65), breaks = c(seq(25,65,5))) + #changer la graduation de l'axe des ordonnées (de 25 à 65, avec un pas de 5)
scale_color_manual (values = c("#1068c9", "#065535"), labels = c("sa mère", "son père")) + #changer les couleurs des courbes et les labels de la légende
labs(x = "Age au départ (ans)", y = "En %", title = "Proportion (%) d'enfants voyant au moins une fois par semaine \nleur père ou leur mère, selon l'âge au départ du foyer parental",
caption = "Champ : Femmes et hommes âgés de 30 à 79 ans, dont les deux parents sont encore en vie\nSource : Ined-Insee, ERFI-GGS, 2005",
color = "Voit au moins\nune fois par semaine :") +
theme_classic() +
theme(plot.title = element_text(face = "bold.italic",
hjust = 0.5), plot.caption = element_text(face = "italic", hjust = 0), axis.title.y = element_text(hjust = 1),
axis.title.x = element_text(hjust = 1))