# Une simple opération sans création d'objet
2*4
# Création de deux objets (a et b) à partir d'opérations arithmétiques
a <- 2*4
b <- 2*6
# Création de l'objet c à partir des objets a et b
c <- a*b
# Création d'un objet A de mode caractère
A <- "Patate"
# Création d'un objet plus complexe (vecteur) qui contient plusieurs valeurs en utilisant la fonction "c(.,.,.)" qui signifie "combiner" et qui va combiner plusieurs valeurs dans un même vecteur:
E <- c(1, 2, 4, 5, 6)Découverte de R et de RStudio
À propos de R
R est un langage de programmation et un logiciel libre principalement destiné à l’analyse statistique et à la science des données.
Il permet:
- de manipuler des données (nettoyage, construction de variables,etc.) ;
- d’analyser des données (analyse descriptive, tests d’hypothèses, modèles multivariés,etc.) ;
- de réaliser une multitude de types de graphiques et de cartes (des plus simples aux plus élaborés) facilement paramétrables ;
- de générer des rapports automatisés reproductibles statiques ou dynamiques comportant des tableaux de données, des statistiques et des visualisations (disponibles aux formats .pdf, .pptx, .docx, .html, .xlsx, etc. avec R Markdown et Quarto ou sous forme d’applications web avec R Shiny).
Pourquoi utiliser R ?
R est un logiciel:
- multiplateforme (fonctionne sur des systèmes Linux, Mac OS et Windows) ;
- libre (développé par ses utilisateurs, diffusable et dont le code source est modifiable par tous) ;
- gratuit ;
- très puissant (les fonctionnalités de base peuvent être étendues à l’aide de nombreuses bibliothèques de fonctions appelées “packages”) ;
- dont le développement est très actif et dont la communauté d’utilisateurs et l’usage ne cessent de s’accroître ;
- avec d’excellentes capacités graphiques ;
- qui permet de produire des documents reproductibles facilitant la transparence et le partage des données dans un contexte de science ouverte.
Les principaux inconvénients de R
- L’interface RStudio, la documentation de référence et les principales ressources sont en anglais ;
- R est un langage de programmation. Il fonctionne à l’aide de scripts (des petits programmes) édités et exécutés au fur et à mesure de l’analyse. La maîtrise du langage R nécessite un temps d’apprentissage mais son acquisition est largement facilitée par les nombreuses formations et ressources disponibles en ligne ;
- L’environnement R comprend un ensemble de fonctionnalités de base qui peuvent être étendues grâce à l’installation de nombreux packages externes (ensemble de fonctions documentées créées par la communauté des développeurs visant à la réalisation d’une tâche particulière comme par exemple l’analyse de variance, la manipulation de données, etc.). L’importation de plusieurs packages incluant des fonctions différentes mais avec des noms identiques peut entraîner ce qu’on appelle des “conflits de packages”. Il est possible de les gérer assez facilement sous R mais ces conflits peuvent être parfois déroutants. Pour en limiter l’apparition, il est recommandé d’importer dans son environnement un nombre minimal de packages (uniquement ceux qui couvrent les besoins de l’analyse).
Installer R et RStudio
 Installation de R
Installation de R
Allez sur la page du CRAN: http://cran.r-project.org/ et téléchargez la dernière version de R (install R for the first time) adaptée à votre ordinateur. Une fois le programme d’installation lancé, installez R avec les options par défaut.
![]() Installation de Rstudio
Installation de Rstudio
Une fois R correctement installé, allez sur https://posit.co/download/rstudio-desktop/. Choisissez l’installateur correspondant à votre système d’exploitation et suivez les instructions du programme d’installation.
RStudio est un environnement de développement intégré (IDE): une interface qui facilite le travail avec R, en particulier la gestion des projets et l’import des données. Il permet de consulter ses fichiers de script, la ligne de commande R, les rubriques d’aide, les graphiques, etc.
Note
Il faut privilégier l’installation de R et RStudio sur un lecteur sur lequel vous avez des droits de lecture et d’écriture. Sinon, votre capacité à installer des paquets R risque d’être affectée. Par ailleurs, pour mettre à jour R ou RStudio, il faudra les réinstaller en allant sur les sites web mentionnés ci-dessus et cliquer sur réinstaller. Il n’existe pas de fréquence déterminée à laquelle mettre à jour R et RStudio, mais il importe de vérifier régulièrement sur le site du CRAN la sortie de nouvelles versions du logiciel, car certains packages ne s’installeront pas correctement si votre version de R est trop ancienne.
Travailler en mode projet
Ouvrir le projet RStudio ![]() de la formation (en double-cliquant sur le fichier .Rproj)
de la formation (en double-cliquant sur le fichier .Rproj)
Un projet RStudio sert à organiser son travail et facilite l’accès à tous les fichiers requis pour une analyse (jeu de données, documentation, codes R, …). Dans notre projet RStudio ERFI1, les ressources et supports de la formation ont été organisés dans différents sous-dossiers (créés par l’utilisateur) visibles dans l’onglet Files du quadrant inférieur droit.
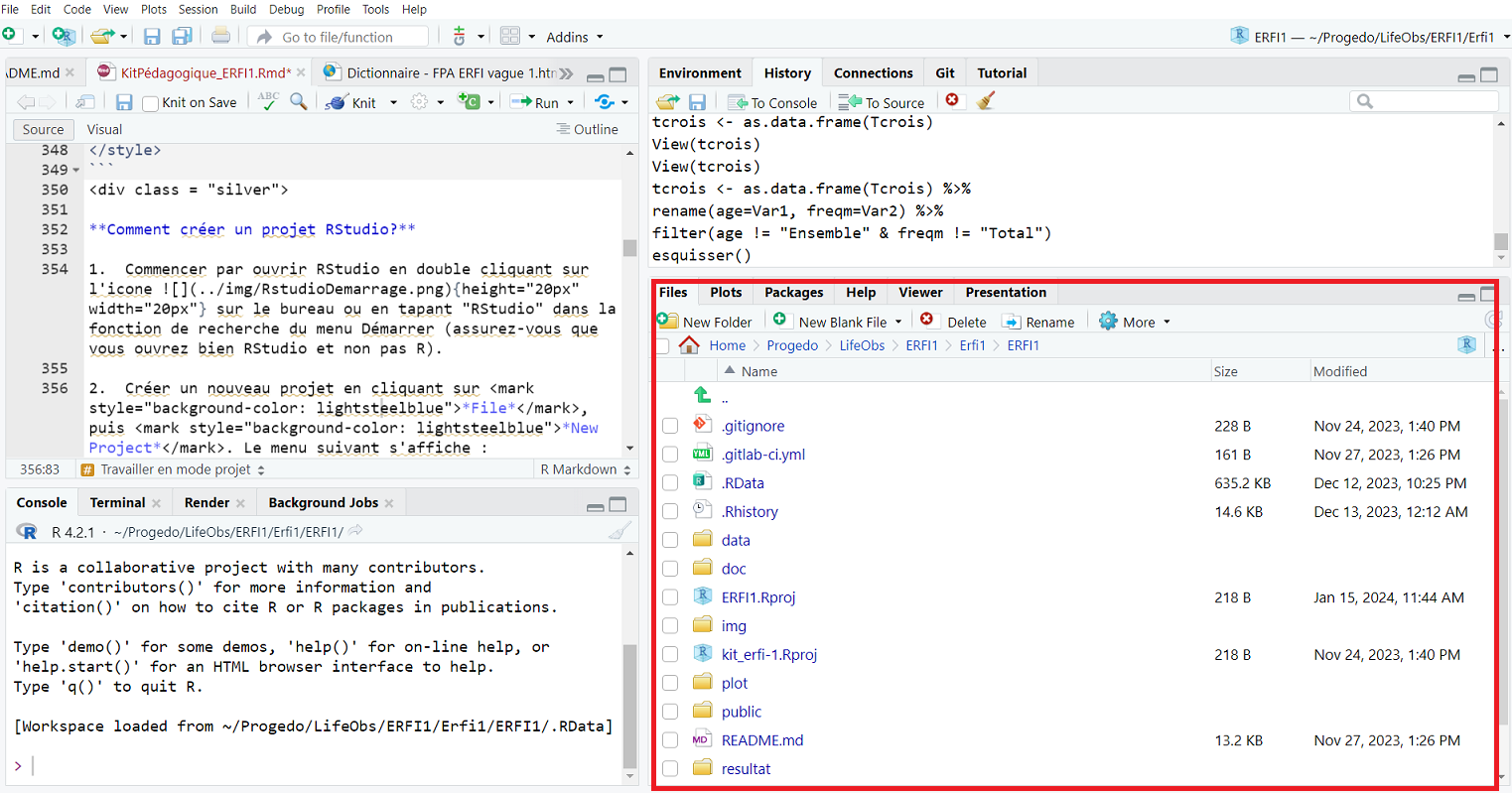
Ces sous-dossiers sont les suivants :
- data/ : ce répertoire contient un jeu de donnée anonymisé et simplifié de l’enquête ERFI-1 en format .csv
- doc/ : ce répertoire contient la documentation et les métadonnées associées à l’enquête originale ERFI-1 en particulier le questionnaire et le dictionnaire des variables, le dictionnaire des variables du fichier anonymisé de l’enquête ERFI-1 utilisé ici, l’article d’Arnaud Régnier Loilier en format .pdf publié en 2006 dans la revue Population et Sociétés dont nous cherchons ici à répliquer certains résultats ainsi que d’autres documents utiles pour la formation (au format .pdf pour la plupart)
- un support de formation en format html réalisé à partir de l’éditeur RMarkdowninclus dans RStudio qui permet de générer des rapports reproductibles au format html (mais aussi pdf, docx, etc.) en mélangeant du texte, du code R et les résultats produits par l’exécution de ce code. Ce support contient l’ensemble détaillé des explications, codes et résultats présentés durant cette formation.
L’utilisation de projets RStudio présente plusieurs avantages :
- faciliter le travail collaboratif en regroupant dans un même dossier de travail (projet) tous les éléments d’une analyse spécifique (données, codes, réglages, documentations, et sorties) à la racine du projet (maîtrise du lieu de sauvegarde, importations et exportations facilitées) ;/
- renforcer la portabilité : le répertoire de travail par défaut d’un projet est le répertoire où est enregistré ce projet. Si vous transmettez le projet à un collègue, le fait de lancer un programme ne dépendra pas de l’arborescence de votre machine. Par exemple, si vous avez un code nommé analyse.R dans votre projet, alors son chemin d’accès ne sera pas “chemin/qui/marche/uniquement/sur/mon/poste/analyse.R” mais “./analyse.R”, quel que soit l’endroit où le projet est enregistré sur votre machine.
Comment créer un projet RStudio?
Commencer par ouvrir RStudio en double cliquant sur l’icone
 sur le bureau ou en tapant “RStudio” dans la fonction de recherche du menu
sur le bureau ou en tapant “RStudio” dans la fonction de recherche du menu Démarrer(assurez-vous que vous ouvrez bien RStudio et non pas R).Créer un nouveau projet en cliquant sur File, puis New Project. Le menu suivant s’affiche :
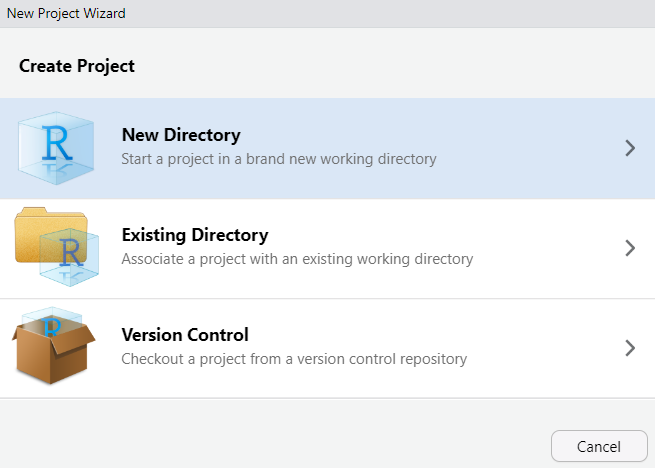
Pour un tout nouveau projet, sélectionnez New Directory, puis New Project. Dans la nouvelle fenêtre qui s’ouvre précisez dans Directory name le nom de votre projet (privilégiez des noms simples et explicites, ne pas utiliser d’espace, d’accent ou de caractères spéciaux) puis dans Create project as subdirectory of indiquez l’endroit où vous souhaitez créer le répertoire de travail du projet sur votre machine (cliquez sur le bouton Browse).
Votre projet RStudio est créé et apparaît dans le quadrant inférieur droit de l’interface RStudio (onglet Files). Il faut maintenant créer les sous-dossiers (data, script, ..) permettant de classer les différents documents de votre projet. Il n’y a pas de régles précises concernant la création de ces sous-dossiers (nombre, nom) mais en général on propose une organisation des données du projet sous cette forme:
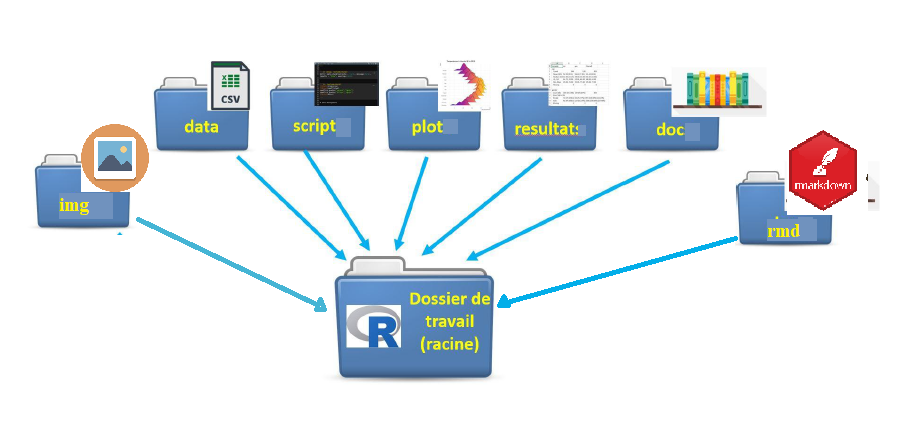 .
.
- Pour créer chacun de ces sous-dossiers, il faut cliquer sur le bouton New Folder dans le menu en haut de l’onglet Files du quadrant inférieur gauche:
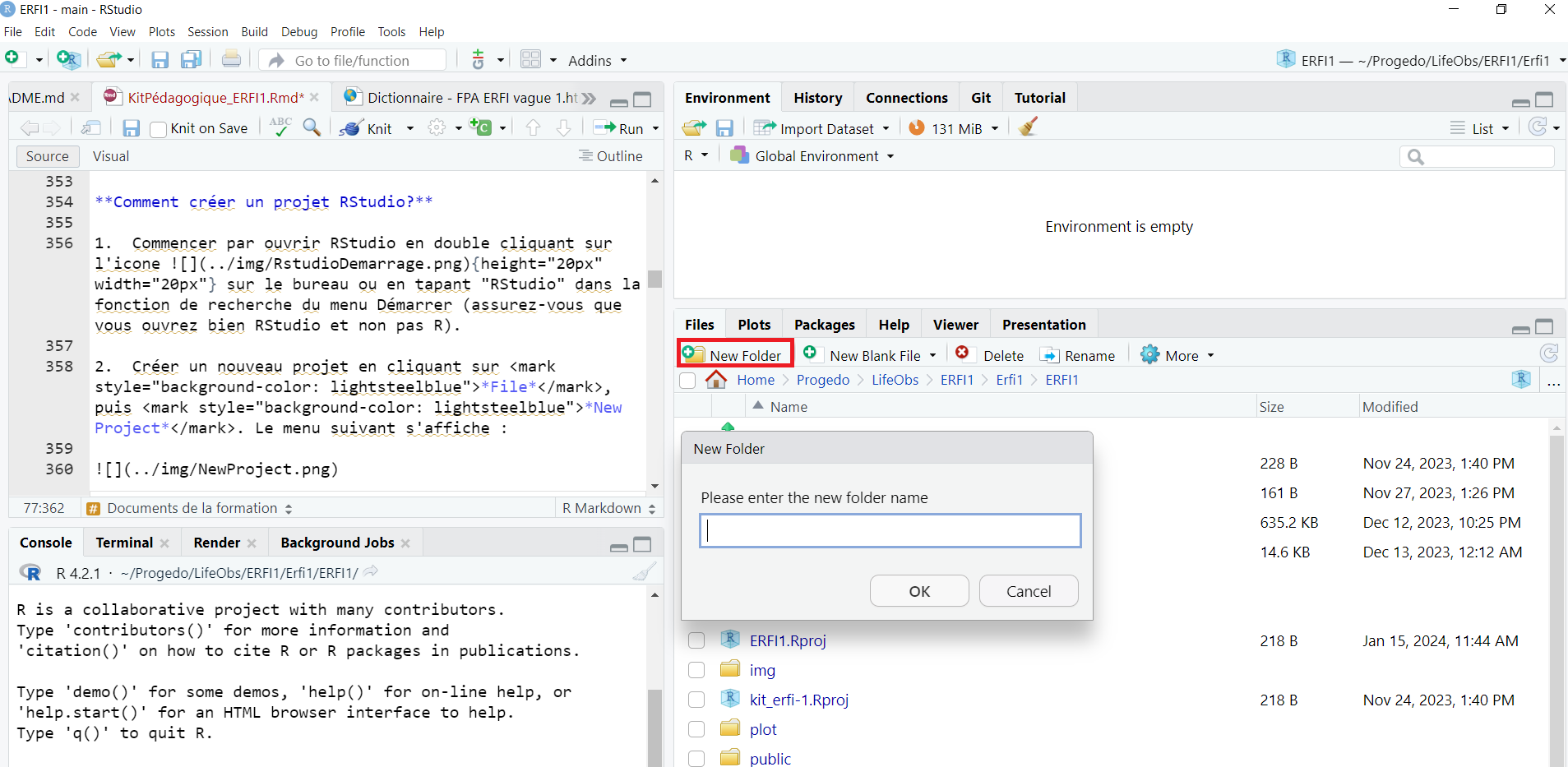
Une fois l’ensemble des sous-dossiers créés, allez dans le répertoire du dossier de votre projet sur votre machine et déplacer chacun de vos documents dans le sous-dossier correspondant (le jeu de données dans data, les documents dans doc, …)
Après avoir suivi toutes ces étapes, vous avez un dossier de travail et un nouveau projet RStudio qui lui est associé.
Note
Pour ouvrir un projet RStudio existant depuis l’interface RStudio, il suffit de cliquer sur le menu File en haut de l’interface RStudio puis de sélectionner l’option Open project et d’indiquer le chemin du répertoire de travail du projet RStudio sur votre machine. Une nouvelle session RStudio s’ouvre dans laquelle le répertoire de travail (working directory) est le dossier-maître du projet (le dossier dans lequel se situe le fichier .Rproj du projet).
Pour plus d’informations sur la création de projet RStudio, n’hésitez pas à consulter la documentation de l’INSEE consacrée à R utilitR, en particulier cette section
L’environnement RStudio
L’ouverture du projet RStudio ![]() ouvre automatiquement une nouvelle session RStudio. Par défaut, au premier lancement de RStudio, l’interface est organisée en trois grandes zones. Pour ouvrir une quatrième zone en haut à gauche de l’interface de RStudio (la zone 2 Scripts sur l’image), il suffit de sélectionner le menu File, puis New file et R script.
ouvre automatiquement une nouvelle session RStudio. Par défaut, au premier lancement de RStudio, l’interface est organisée en trois grandes zones. Pour ouvrir une quatrième zone en haut à gauche de l’interface de RStudio (la zone 2 Scripts sur l’image), il suffit de sélectionner le menu File, puis New file et R script.
L’interface de RStudio: 4 grandes zones
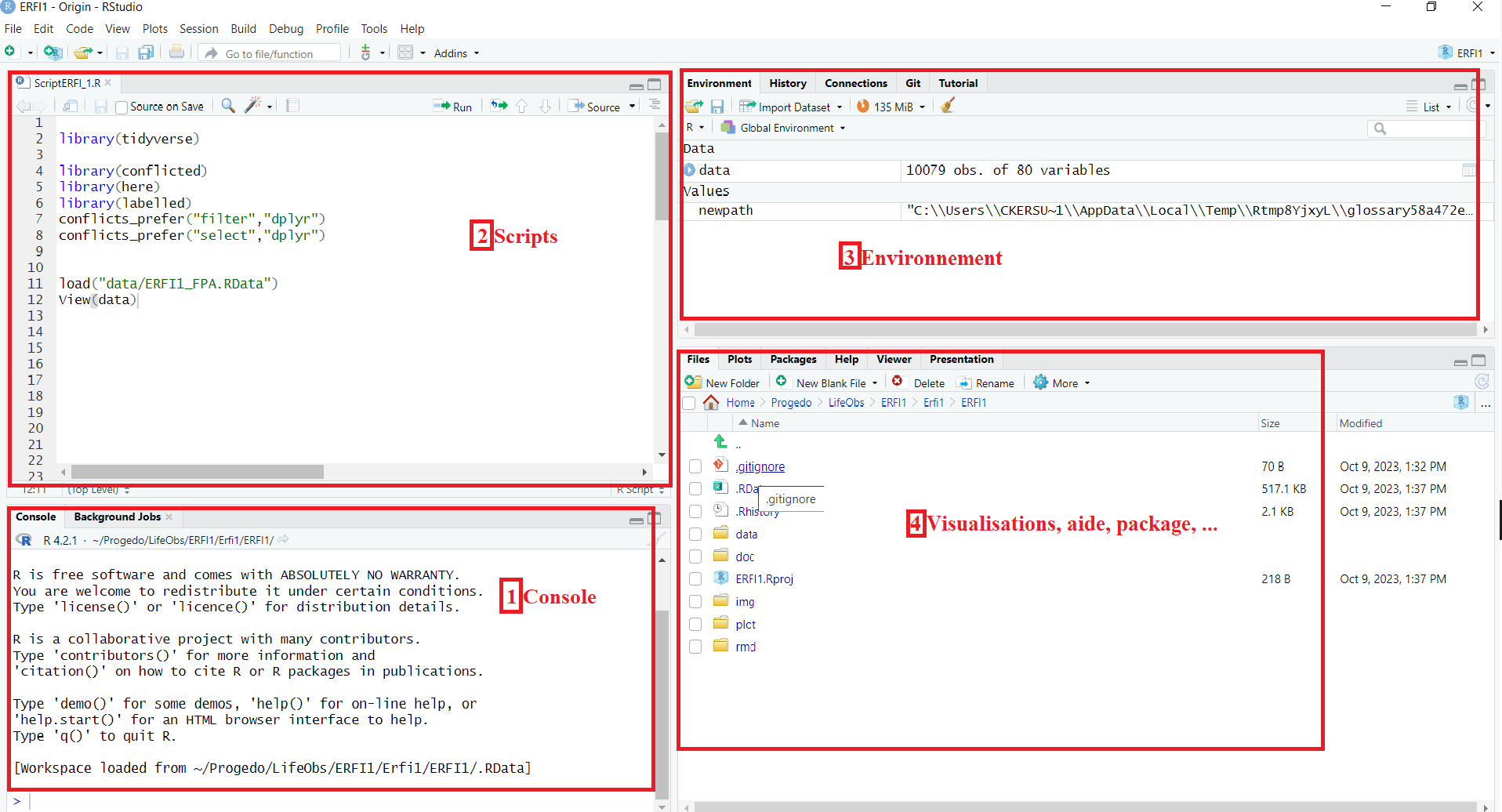
L’interface de RStudio est maintenant divisée en quatre quadrants :
- 1 Console (quadrant inférieur gauche)
C’est la fenêtre de commande : c’est là que les commandes R sont réellement exécutées et que les sorties non graphiques et les messages d’erreur/d’avertissement apparaissent.
Les instructions données à R (commandes ou fonctions) peuvent être saisies et exécutées directement dans la console R (en validant une instruction par la touche Entrée) mais ces commandes ne pourront pas être enregistrées (contrairement à celles saisies et exécutées à partir d’un script)
- 2 Scripts (quadrant supérieur gauche)
C’est un fichier texte (éditeur) où l’on écrit les instructions données à R qui seront ensuite transférées dans la console pour être exécutées. Les scripts peuvent être enregistrés. C’est pourquoi il est préférable d’écrire les commandes R dans un script et de le sauvegarder.
Enregistrez votre script dans le sous-dossier script du projet RStudio ERFI1 sous le nom ERFI1_Regnier.r (menu File, Save As).
On peut envoyer les codes de la zone Script vers la zone Console: grâce au bouton  (qui exécute la ou les lignes de commande sélectionnée(s)) ou en appuyant simultanément sur les touches clavier Ctrl + Enter pour Windows / Cmd + Enter pour Mac.
(qui exécute la ou les lignes de commande sélectionnée(s)) ou en appuyant simultanément sur les touches clavier Ctrl + Enter pour Windows / Cmd + Enter pour Mac.
- 3 Environnement (quadrant supérieur droit)
Ce quadrant offre différentes options :
- une liste de l’ensemble des objets et datasets (données importées, modifiées ou créées, paramètres définis, …) en mémoire (onglet Environment),
- un outil d’importation de données (bouton Import Dataset dans l’onglet Environment),
- un historique de vos commandes R (onglet History).
- 4 Visualisation, aide (quadrant inférieur droit)
Ce quadrant permet d’accéder aux:
- fichiers de votre projet R ou répertoire de travail (onglet Files),
- graphiques réalisés grâce aux instructions R (onglet Plots),
- extensions disponibles avec la possibilité de les installer directement depuis l’interface (onglet Packages),
- documentations et fichiers d’aide en ligne (onglet Help),
- Viewer utilisé pour visualiser certains résultats (notamment les graphiques) au format web (html).
Utiliser la console ou un script pour taper les instructions données à R ?
Pour répondre, la question essentielle à se poser est : si je dois refaire mon analyse demain, est-ce que j’aurais à nouveau besoin de cette instruction ?
- instructions qui modifient R ou Rstudio, par exemple l’installation de packages ou leur mise à jour-> dans la console
- instructions qui me permettent de savoir où j’en suis dans mon analyse, par exemple visualisation de mes objets -> le plus souvent dans la console
- instructions qui ont pour but de créer des variables/valeurs et/ou qui produisent des résultats statistiques -> dans le script
Les objets
Un objet est l’unité de base dans R : les données sont sauvegardées dans des objets, on manipule et on travaille avec ces objets, et on exécute des opérations sur ces objets. Ces objets peuvent contenir tout types et structures de données. Les données doivent donc être stockées dans un objet pour pouvoir être manipulées (même si les données peuvent apparaitre dans la console, R ne pourra pas travailler dessus si elles ne sont pas stockées dans un objet).
Pour créer un objet dans R (assigner des données à un objet), on utilise le plus souvent l’opérateur d’assignation <- (inférieur à, suivi d’un tiret sans espace entre les deux).
Il s’emploie ainsi : nom_objet <- valeur ou opération. Si aucun objet dont le nom est nom_objet n’existe dans votre environnement de travail, l’objet nom_objet est créé et comprend la valeur ou l’opération affectée ; si un objet de ce nom existe déjà, il disparaît et est remplacé par la nouvelle valeur ou opération affectée.
Note
Si vous modifiez un objet contenant vos données d’origine en créant un nouvel objet du même nom, vous écrasez les données d’origine mais cela ne signifie pas pour autant que vos données initiales sont perdues. Il est toujours possible de revenir en arrière en réimportant les données d’origine dans l’environnement R ou en relancant les lignes précédentes de votre script.
Les noms des objets
Vous pouvez choisir librement le nom des objets mais privilégiez des noms courts et explicites (afin de comprendre ce que votre objet contient). Par ailleurs, il existe 4 régles importantes pour le nom des objets dans R:
- Ils ne peuvent pas commencer par un chiffre
- Pas d’accent, pas d’espace, pas de caractères spéciaux : utiliser des underscores (donnees_menages) ou CamelCase (DonneesMenages)
- R est sensible à la casse (différencie les majuscules des minuscules : A et a sont des objets différents)
- Ne pas utiliser des abréviations de fonction R (mean, …)
La plupart du temps, les objets sont créés à partir d’un autre objet, de valeurs numériques ou caractères ou encore d’une sortie d’une opération (fonction)
Exemple
Lorsqu’on exécute ces commandes (bouton ou touches clavier Ctrl + Enter pour Windows / Cmd + Enter pour Mac), les objets ne s’affichent pas directement dans la console mais 5 objets (a, b, c, A, E) font désormais partie de notre environnement de travail (onglet Environment du quadrant supérieur droit de Rstudio). Nous pouvons désormais manipuler ces objets.
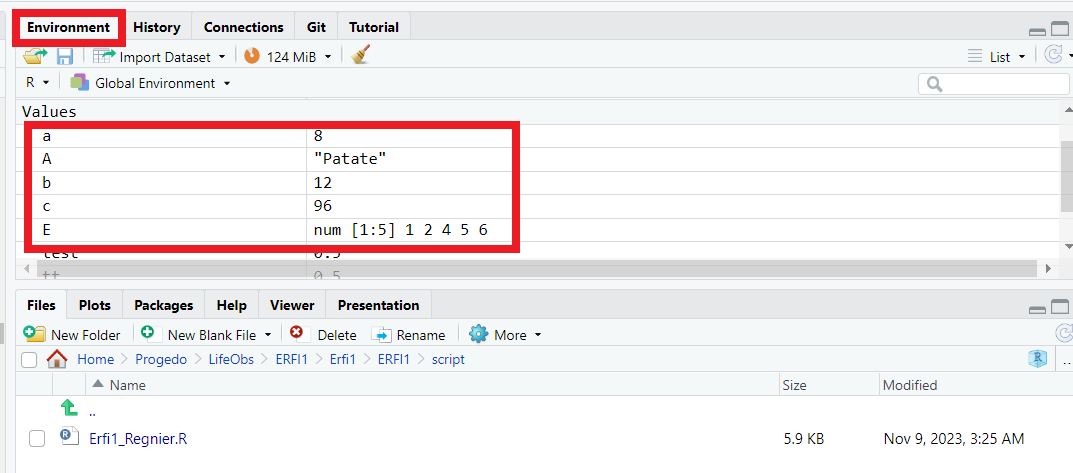
Affichage ou suppression des objets
Quelques commandes (ou fonctions) utiles à exécuter dans la console ou le script pour afficher ou supprimer un ou des objet(s).
| Commande (fonction) | Description |
|---|---|
|
Afficher la liste de tous les objets dans l’environnement R |
|
Afficher le contenu de l’objet ‘a’ |
|
Supprimer l’objet ‘a’ de l’environnement |
|
Supprimer l’objet ‘a’ et ‘b’ de l’environnement |
|
Supprimer tous les objets de l’environnement |
Dans R, les objets se différencient par leur mode (c’est à dire par leur contenu) et par leur classe (c’est à dire par la structure des informations qu’ils comportent/la manière dont les informations sont stockées et organisées par R). Cette distinction est importante car la plupart des opérations (fonctions) s’appliquent à une classe d’objet spécifique.
Il existe 3 principaux modes pour les objets R :
- numeric : des nombres entiers (en anglais integer comme 3, 4, 12, …) ou réels (en anglais double qui correspondent à des nombres décimaux tels que 1.4, 1.0, 12.5, …),
- character : des chaînes de caractère c’est à dire du texte (que l’on créé à l’aide de guillemets comme “nom”, “ouvrier”, …),
- logical : des valeurs logiques de type “vrai” ou “faux” (TRUE, FALSE)
Quel que soit le mode d’un objet, les valeurs manquantes sont toujours représentées par NA (qui signifie Not Available).
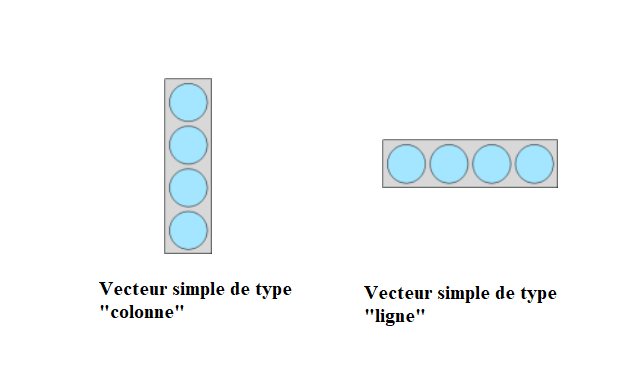
Le vecteur est la structure de base des objets dans R: tous les objets R sont formés d’un ou plusieurs vecteurs. On distingue les vecteurs simples (1) des vecteurs composites (2)
Les vecteurs simples représentent une liste de données de même type/mode. Ils sont très fréquents : on les utilise pour représenter les données d’une variable statistique comme par exemple la liste des revenus ou encore la liste des noms. Les objets de type “vecteur simple” peuvent être vus comme une colonne ou une ligne de valeurs toutes du même mode dont la structure est la suivante:
Pour connaître la nature d’un objet, on utilise la commande (fonction) class. Par exemple :
# Création du vecteur simple "a"
a <- c(1,2,5)
# Interroger la classe du vecteur "a"
class(a)[1] "numeric"# Supprimer l'objet "a" de l'environnement
rm(a)- Les vecteurs composites qui sont des assemblages de vecteurs simples et qui ont donc plusieurs dimensions (plusieurs colonnes et plusieurs lignes).
Il y a plusieurs classes de vecteurs composites mais ici nous allons uniquement nous intéresser à la classe data.frame car la majeure partie des données d’enquête se présente sous la forme de data frame.
La plupart des jeux de données d’enquête (dataset en anglais) se présente sous la forme d’un tableau où chaque ligne correspond à une observation (individu) et chaque colonne à une caractéristique (variable). Dans R, les data frame sont des classes d’objet qui permettent de stocker de tels jeux de données. Les colonnes d’un data frame (variables d’un jeu de données) sont toujours nommées (noms des variables d’un jeu de données). Dans la plupart des cas, chacune de ces colonnes (variables) peut être vue comme un vecteur colonne simple de même longueur (même nombre de lignes). Les lignes d’un data frame sont quant à elles automatiquement numérotées par ordre (1 = première ligne, 2 = deuxième ligne,…).
Organisation des données dans un data frame

Les informations (valeurs) des différentes colonnes d’un data frame peuvent être de différents modes (entier, réel, logique, caractère, …) ce qui correspond dans les faits à la nature des différentes variables d’un jeu de données (quantitatives: classes numeric, integer,… ou qualitatives: classes character, logical, factor,..).
Note
Les variables d’un jeu de données peuvent être classées en deux catégories:
1. Les variables quantitatives qui permettent de mesurer une grandeur (quantité). On distingue les variables quantitatives continues (pour lesquelles il y a un nombre infini de valeurs possibles comme par exemple la taille, le revenu, la surface, etc.) et les variables quantitatives discrètes (pour lesquelles il y a un nombre fini de valeurs comme par exemple le nombre de pièces du logement, le nombre d’enfants, etc.)
2. Les variables qualitatives qui indiquent des caractéristiques qui ne sont pas des quantités. Les différentes valeurs d’une variable qualitative sont appelées des modalités. On distingue les variables qualitatives ordonnées (pour lesquelles il existe un ordre des modalités comme par exemple la satisfaction sur une échelle, etc.) des variables qualitative non ordonnées/nominales (pour lesquelles il n’y pas d’ordre dans les modalités comme par exemple le sexe, la couleur des yeux, etc.). On parle aussi parfois de variable qualitative binaire ou dichotomique (de type oui/non ou vrai/faux).
Exemple de data frame dans R
Utilisation de la commande/fonction head(nom_dataframe) qui permet d’afficher les 10 premières lignes d’un dataframe (ici du data frame nommé df1)
#Utilisation de la fonction head() pour afficher les 6 premières lignes du data frame df1
head(df1) var1 var2 var3
1 1 a TRUE
2 2 b FALSE
3 3 c TRUE
4 4 d FALSE
5 5 e TRUE
6 6 f FALSE#Interroger la classe de "df1"
class(df1)[1] "data.frame"#Interroger la classe de "var1" du data.frame "df1"
class(df1$var1)[1] "integer"
Note
Dans R, on accéde aux variables d’un data frame avec l’opérateur $.
df1$var1 signifie donc la variable var1 du data frame df1.
Par ailleurs, R est sensible à la casse ce qui signifie que si vous tapez df1$Var1 au lieu de df1$var1 alors R enverra un message d’erreur dans la console de type Unknown or uninitialised column: df1$Var1 car il ne connaît pas la variable df1$Var1 .
Exemple
Utilisation de la fonction str(nom_data_frame) qui permet de visualiser la classe de chacune des variables (ou vecteurs) de l’objet data frame nommé nom_data_frame.
str(df1) 'data.frame': 10 obs. of 3 variables:
$ var1: int 1 2 3 4 5 6 7 8 9 10
$ var2: chr "a" "b" "c" "d" ...
$ var3: logi TRUE FALSE TRUE FALSE TRUE FALSE ...Les fonctions
Une autre façon usuelle d’interagir avec R est d’utiliser des fonctions qui permettent d’effectuer des tâches et des opérations. Les fonctions disponibles au sein des bibliothèques (packages) sont des outils qui permettent d’exécuter rapidement des opérations sur des objets sans avoir à écrire toutes les étapes mathématiques ou logiques. On en a déjà utilisé plusieurs dans la partie précédente telles que class(nom_objet) ou encore head(nom_data_frame). Un certain nombre de fonctions de base sont installées avec R (appelées les fonctions base-R), beaucoup d’autres sont disponibles dans des packages à télécharger.
Une fonction R s’écrit avec des parenthèses, entre lesquelles l’utilisateur précise la valeur des argument(s)/paramètre(s), sous cette forme : fonction(argument1, argument2, …). Ces arguments peuvent être obligatoires (la fonction ne peut pas fonctionner si ces arguments ne sont pas fournis par l’utilisateur) ou au contraire optionnels.
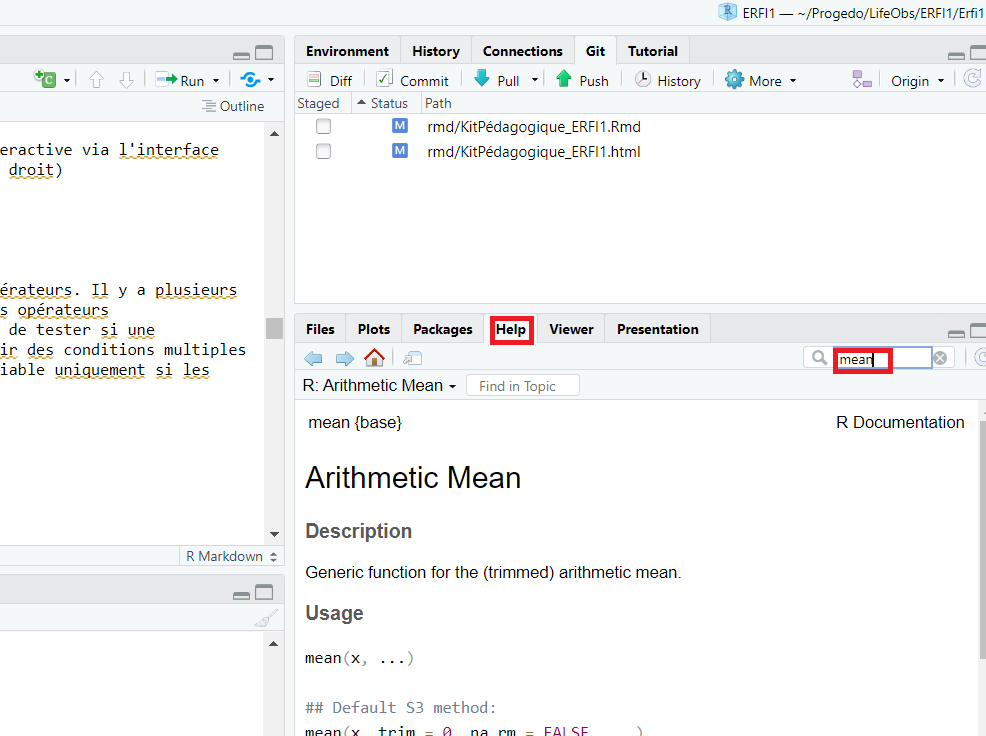
Il est très fréquent de ne plus se souvenir quels sont les arguments d’une fonction ou le type de résultat qu’elle produit. Dans ce cas, on peut très facilement accéder à l’aide R décrivant une fonction particulière en tapant help dans la console (quadrant inférieur gauche) ou dans un script (quadrant supérieur gauche):
help(nom_fonction)
#ou
?nom_fonctionExemple : avec la fonction mean (du package R base)
help(mean)Une fois la commande exécutée, le fichier d’aide associé à la fonction mean apparait dans le quadrant inférieur droit sous l’onglet Help et fournit ces informations:
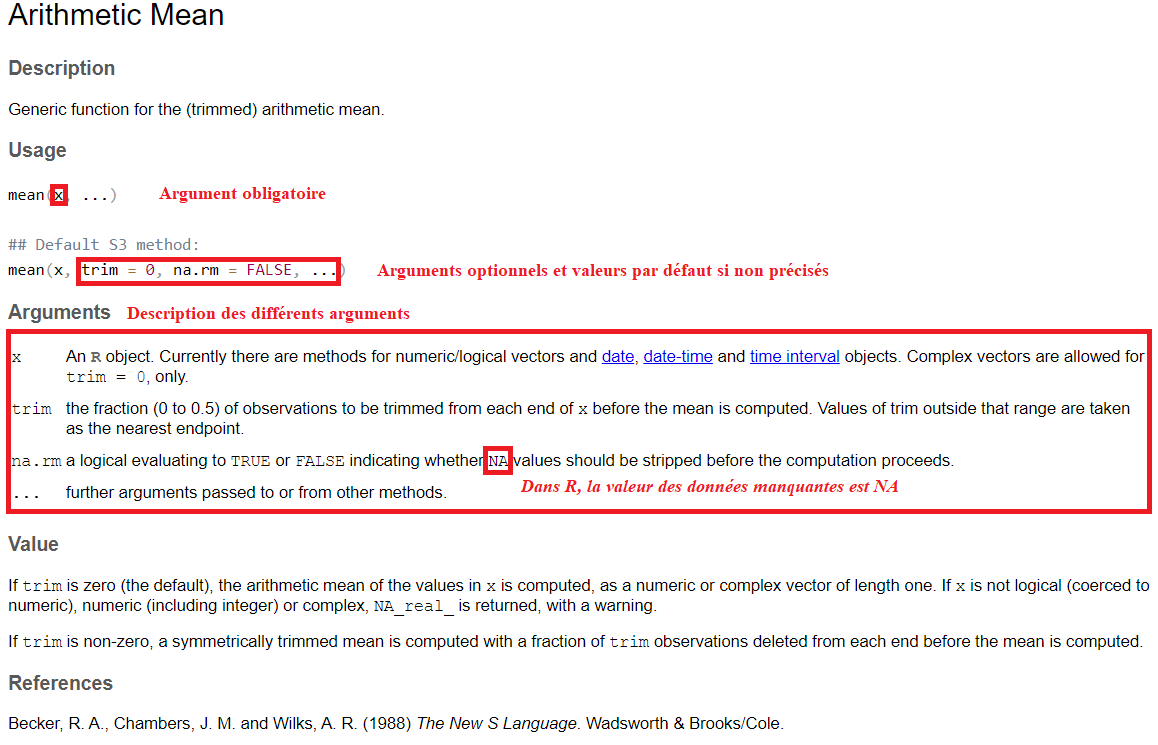
Grâce à ce fichier d’aide en anglais, on peut obtenir une description de la fonction et voir qu’il y a trois arguments/paramètres pour la fonction mean:
- x (argument obligatoire) qui précise la série de valeurs (généralement numériques) sur laquelle est calculée la moyenne
- trim (argument optionnel avec comme valeur par défaut trim=0) est une fraction entre 0 et 0.5 d’observations à supprimer au début et à la fin de la série de valeurs x pour le calcul de la moyenne
- na.rm (argument optionnel de type logique TRUE/FALSE avec comme valeur par défaut na.rm=TRUE) qui précise si les valeurs manquantes (notées
NAdans R) de la série x doivent être supprimées (na.rm=TRUE) ou conservées (na.rm=FALSE) pour le calcul de la moyenne.
Exemple : calcul de la moyenne de la variable “var1” du data frame “df1”
mean(x=df1$var1, trim=0, na.rm=TRUE)[1] 5.5# ou avec les arguments par défaut
mean(df1$var1)[1] 5.5On pourra aussi utiliser la fonction apropos("mot clé")qui peut être utile quand on ne connaît pas la fonction nécessaire pour réaliser une opération.
Pour rechercher de l’aide, il est également possible de le faire directement de façon interactive via l’interface RStudio à travers l’onglet Help du quadrant Visualisation, Aide (quadrant inférieur droit).
Les opérateurs
A côté des fonctions, une autre façon d’interagir avec des objets R est d’utiliser des opérateurs. Il y a plusieurs type d’opérateurs dans R : les opérateurs arithmétiques de base (+, -, *, /, ^, …), les opérateurs logiques/relationnels et les opérateurs de comparaison. Ils peuvent par exemple permettre de tester si une déclaration est vraie ou fausse (en comparant deux éléments entre eux), ou encore de définir des conditions multiples sur des opérations/fonctions (par exemple lorsqu’on veut calculer une moyenne sur une variable uniquement si les valeurs d’une autre variable sont inférieures à 30).
Les principaux opérateurs logiques et de comparaison dans R sont les suivants :
| Opérateur | Rôle | Exemple d’utilisation |
|---|---|---|
| > | Strictement supérieur à | |
| >= | Supérieur ou égal à | |
| < | Strictement inférieur à | |
| <= | Inférieur ou égal à | |
| == | Egal à | |
| != | Différent de | |
| & | ET (l’un et l’autre) | |
| | | OU (l’un ou l’autre) | |
Exemple d’utilisation des opérateurs
#Utilisation de la fonction head() pour afficher les 6 premières valeurs de la variable var1 du data frame df1
x <- head(df1$var1)
print (x)[1] 1 2 3 4 5 6# Tester la condition selon laquelle les premières valeurs de var1 du data frame df1 sont inférieures ou égales à 4 (renvoie "TRUE" si oui, "FALSE" si non)
y <- head(df1$var1 <= 4)
print (y)[1] TRUE TRUE TRUE TRUE FALSE FALSE# Les opérateurs logiques et de comparaison fonctionnent aussi pour formuler des expressions (conditions) sur les fonctions
z <- mean(df1$var1)
print (z)[1] 5.5za <- mean((df1$var1 <= 4) & (df1$var3 == "TRUE"))
print (za)[1] 0.2Les packages
Un package est un ensemble de fonctions partageant un objectif similaire (par exemple le calcul de statistiques, la réalisation de graphiques, etc.) développées par des utilisateurs de R, qui améliorent ou étendent les fonctionnalités de base de R (exemple de packages: ggplot2, tidyverse,etc.). Certains packages ont des dépendances (dependencies) c’est à dire qu’il est nécessaire de télécharger d’autres packages pour les faire fonctionner (le téléchargement des dépendances lors de l’installation d’un package dans R est par défaut réalisé automatiquement)
Les packages sont disponibles sur des sites «dépôts» (repositories), le dépôt officiel est le CRAN. Actuellement, il existe à peu près 20 000 packages disponibles sur le CRAN.
Pour utiliser un package R, il est nécessaire de réaliser 2 actions :
- Le téléchargement : télécharger le package sur internet, puis l’installer sur l’ordinateur, dans un dossier de R. Il y a 2 solutions pour installer un package:
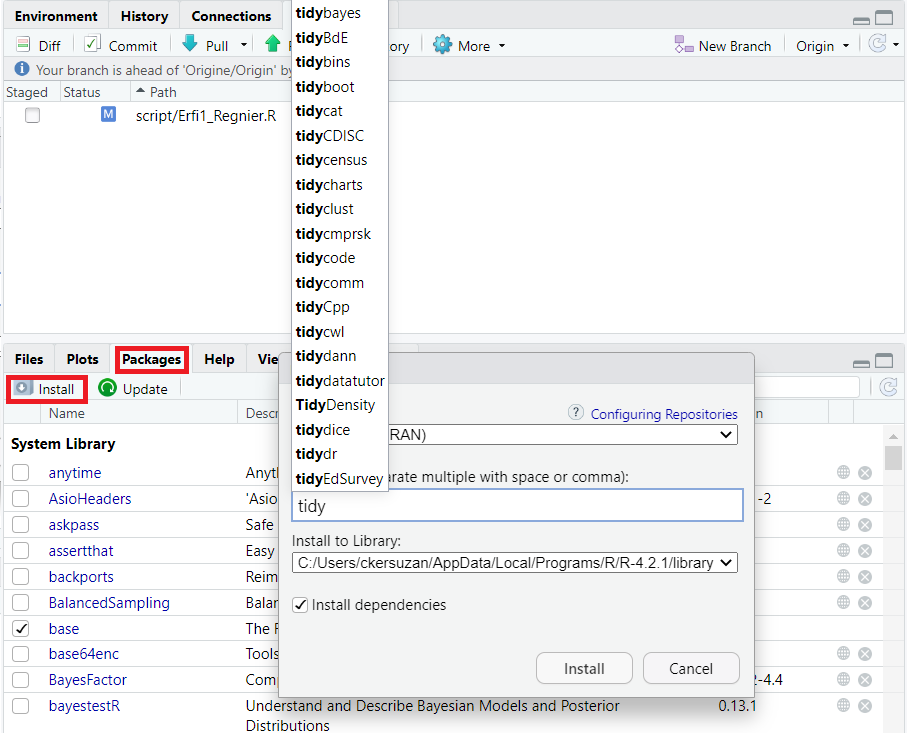
install.packages("nom_du_package", dependencies = TRUE)
# Lorsque plusieurs packages doivent être installées, on pourra utiliser l'opérateur c(" ", " ", "...") de cette manière:
install.packages(c("nom_du_package1", "nom_du_package2", "nom_du_package3"))- le chargement du package : indiquer à R que l’on souhaite utiliser le package pour la session en cours. Pour cela, il suffit d’écrire library(nom_du_package) dans votre script :
library(nom_du_package)Le téléchargement et le chargement du package sont deux actions différentes. Le téléchargement est une opération à réaliser une seule fois : une fois qu’un package a été téléchargé et installé, il est présent sur son ordinateur de façon permanente. En revanche, le chargement ou l’installation d’un package doit être réalisé à chaque fois que vous avez besoin du package dans une session R.
Note
Les packages sont spécifiques à une version minimale de R (s’il y a une mise à jour de R, il pourra aussi être nécessaire de mettre à jour les packages) Pour mettre à jour un package, il suffit de le réinstaller avec la fonction install.packages.
Bonnes pratiques de programmation
Pour faciliter la lecture d’un code R et sa compréhension (afin qu’il puisse être réutilisé ou corrigé par vous-même mais aussi par d’autres personnes), il est important d’adopter de bonnes pratiques de programmation (respecter certaines normes pour créer du “bon code”). Il existe de nombreuses ressources en ligne qui renseignent les bonnes pratiques de programmation dans R comme par exemple en français le “Guide des bonnes pratiques en R” (INSEE, DREES).
Parmi les pratiques recommandées, on trouve notamment les régles suivantes :
- Travailler en mode “Projet” dans Rstudio (créer un environnement dans lequel on a les données, les scripts, l’historique) ;
- Écrire dans un script et non dans la console (pour ne pas perdre l’historique de ses actions) ;
- Aller à la ligne pour chaque nouvelle instruction R et utiliser des espaces avant et après les opérateurs ;
- Commenter, expliquer son code et documenter les fonctions écrites par l’utilisateur (ce que fait la fonction, les arguments acceptés en entrée, les résultats produits) en utilisant l’opérateur
#;
- Tester son code régulièrement ;
- Utiliser des outils de contrôle de version tel que git (permet un suivi des évolutions d’un fichier bloc par bloc et contributeur par contributeur) ;
- Utiliser l’opérateur « pipe » du package magrittr (noté
%>%) pour enchainer les fonctions. Il peut se traduire par “et puis”.
L’opérateur “pipe” du package magrittr (noté %>%)
Quand on manipule des données, il est très fréquent d’enchaîner plusieurs opérations (par exemple calculer la moyenne puis l’arrondir et afficher le résultat ou encore extraire une sous-population, sélectionner des colonnes puis trier selon une variable). Dans ce cas, plusieurs méthodes peuvent être employées.
Prenons un exemple, on souhaite:
- Créer un vecteur numérique (en utilisant la fonction
c()) - Calculer la moyenne de ce vecteur (en utilisant la fonction
mean()) - Ajouter +1.96 à la valeur de la moyenne calculée
- Arrondir la valeur du résultat à un chiffre après la virgule (en utilisant la fonction
round(nom_objet, digits=1)où l’argument digits indique le nombre de décimales/le nombre de chiffres après la virgule) - Changer l’opérateur décimal «.» par le format français «,».
Pour réaliser ces différentes opérations, il y a plusieurs méthodes:
- Effectuer les opérations les unes après les autres, en stockant les résultats intermédiaires dans un objet temporaire.
Pour notre exemple, le code est le suivant:
#1. Création du vecteur numérique "a"
a <- c(5, 6, 8, 10, 15, 20)
#2. Calculer la moyenne du vecteur en créant l'objet "b"
b <- mean(a, na.rm=FALSE)
#3. Ajouter 1.96 au résultat en créant l'objet "c"
c <- b + 1.96
#4. Arrondir le résultat dans l'objet "d"
d <- round(c, digits=1)
#5. Changer le format de l'opérateur décimal "." en ","
e <- format(d, decimal.mark = ",")
print(e)[1] "12,6"Cette écriture n’est pas du tout optimale, car elle entraîne la création d’un grand nombre de variables intermédiaires (b, c, d) totalement inutiles.
- Effectuer toutes les opérations en une fois en les “emboîtant”. Pour notre exemple, le code est le suivant:
a <- c(5, 6, 8, 10, 15, 20)
format(round((mean(a) + 1.96), digits = 1), decimal.mark = ",")[1] "12,6"Le résultat est identique mais cette ligne de code qui imbrique plusieurs fonctions les unes dans les autres est peu lisible. Il n’est pas facile de savoir à quelle fonction est rattaché chaque argument.
- Utiliser le “pipe” (
%>%) qui permet de combiner une suite d’instructions R à travers une lecture facile sans avoir à créer des objets intermédiaires inutiles. Pour notre exemple, le code est le suivant :
# Charger le package tidyverse qui inclut dans ses dépendances le package magrittr qui fournit l'opérateur pipe noté %>%
library(tidyverse)
a <- c(5, 6, 8, 10, 15, 20) %>%
mean() %>%
+ 1.96 %>%
round(digits=1) %>%
format(decimal.mark = ",") %>%
print(a)[1] "12,6"Le principe du chaînage (ou pipe en anglais) noté %>% est de passer l’élément situé à sa gauche comme premier argument de la fonction située à sa droite. Il permet ainsi de combiner une suite d’instructions R en évitant d’avoir à répéter le nom des objets (ou de créer des objets intermédiaires) ou encore d’imbriquer des fonctions. Il rend donc le code plus lisible et doit être privilégié pour les manipulations complexes de données.
Note
À partir de la version 4.1 de R, l’opérateur pipe est directement disponible dans les paquets de base de R. Il est noté |>. Les deux opérateurs %>% et |> peuvent être utilisés dans la plupart des cas de manière interchangeable.